802 Matching Annotations
- Jul 2026
-
www.techradar.com www.techradar.com
-
github.com github.comFAQ1
-
However, it’s important not to confuse the concept of being scammed (social engineering) with being hacked (technical breaches).
-
-
-
Hiding the signal in the system prompt makes every other privacy claim harder to believe.
指出将信号隐藏在系统提示符中使得其他隐私声明更难以相信,强调了透明度的重要性。
-
-
-
We are also working with enterprise customers on longer-term approaches—including privacy-preserving detection, customer-operated safety controls, and access calibrated to the risk of a customer, user, or workload—to advance safety while supporting enterprise privacy requirements.
这句话提到了OpenAI与企业客户合作,以更长期的方法来提高安全性,同时支持企业的隐私要求。需要深入了解这些长期方法的细节和效果。
-
- Jun 2026
-
www.wired.com www.wired.com
-
At WWDC 2026, Apple repeatedly referenced its privacy-preserving approach to Siri AI. As part of the company's Private Cloud Compute, Apple claims it doesn't store data from users and only pulls from it when you ask Siri a question.
大多数人认为大型科技公司提供的AI服务必然会收集和存储用户数据以改进产品,但作者指出苹果声称其Siri AI采用隐私保护设计,只在用户提问时才访问数据。这一声明挑战了当前AI行业普遍依赖数据收集的做法,暗示苹果可能找到了一种既能提供AI功能又能保护隐私的新模式。
-
-
www.tomtunguz.com www.tomtunguz.com
-
Privacy, zero cost, & complete offline capability matter.
本地编码模型的核心优势在于隐私保护、零成本和完全离线能力。对于处理敏感代码或需要稳定网络环境的开发者来说,这些优势尤为重要。在选择编码工具时,应权衡这些因素与云端模型的便利性和高级功能。
-
-
natcwik.substack.com natcwik.substack.com
-
A public dataset is not encountered in the same way by every actor. For one community, it may be a tool for language preservation, research or local innovation. For a large company, it may become one more input into a product that returns little value to the people represented in the data.
-
-
www.wired.com www.wired.com
-
A newly disclosed letter shows the warnings went unheeded: US Central Command now confirms it has received “multiple threat reports concerning adversary exploitation of commercial location data to target or surveil US personnel in theater”—the first official acknowledgment that the data-broker economy is being used to hunt American forces in the Middle East.The targeting was first reported by Reuters, which obtained the Centcom letter. But the confirmation lands atop a record that is longer and more damning than the single document suggests.
-
-
techcrunch.com techcrunch.com
-
Before rolling out the enhancements and features, Apple was adamant about its privacy-centric approach to AI. 'We believe privacy in AI is non-negotiable,' Apple Senior Vice President Craig Federighi said during the stream
大多数人认为在AI竞赛中,苹果会像其他科技巨头一样,为了提升AI功能而牺牲部分隐私保护。然而,苹果却强调隐私是其AI策略的核心,这与行业普遍认为AI需要大量用户数据才能有效发展的共识相悖,表明苹果在AI领域坚持其隐私至上的价值观,即使这可能限制其AI功能的先进性。
-
-
blog.includesecurity.com blog.includesecurity.com
-
The Smart TV in Your LivingRoom Is a Node in the AIScraping Economy
- Distributed AI Training and Scraping: AI companies require massive amounts of web-scraped data for training, search, and agent grounding. Because traditional data centers face heavy blocking and throttling by security services (like Cloudflare and DataDome), scrapers rely on residential proxy networks to route traffic through home internet connections.
- Bright Data's SDK Network: Bright Data operates a massive commercial residential proxy network (marketing over 150M+ to 400M+ IPs). They source these exit nodes by embedding a consent-based Software Development Kit (SDK) inside consumer-facing mobile apps and Connected TV (CTV) / Smart TV applications.
- Why Smart TVs are the Ideal Proxies: Compared to mobile phones, Smart TVs provide a near-perfect infrastructure for proxy routing:
- They are permanently connected to high-speed home Wi-Fi and grid power (no battery constraints).
- They run 24/7 in standby mode and offer effectively unlimited bandwidth.
- They operate largely unattended with virtually no corporate or family oversight.
- The consent UI on TVs is typically dense text navigated via remote arrow keys, making it unlikely for users to understand that their bandwidth is being sold to third-party scrapers.
- Deceptive Allocation Limits: While opt-in prompts (such as in the Roku app Petflix) claim the SDK "occasionally" uses free resources, the underlying, publicly queryable SDK configuration sets a massive monthly default Wi-Fi budget of up to 200 GB (
max_bw_monthly_wifi: 200,000,000,000 bytes). - Notable SDK Integration Partners: Public, unauthenticated partner manifest endpoints expose integrations with platforms reaching hundreds of millions of households, including:
- PlayWorks Digital Ltd: Over 400 CTV game titles across Comcast, Sky, Cox, LG, Samsung, Vizio, and Roku.
- CloudTV: Integrated across more than 125 TV brands and 15+ OEMs.
- Viber Media (Rakuten): Massive messaging app ecosystem.
- Supercent & Moonfrog Labs: Major mobile game publishers.
- Technical Reverse-Engineering & VPN Bypasses: Technical analysis of the iOS framework (
brdsdk.framework) reveals that:- The SDK dials out to a persistent WebSocket connection tracking device metrics (CPU, memory, network state, battery level).
- Bypassing VPNs: By forcing network interface bindings directly to Wi-Fi (
en0) or cellular (pdp_ip0) instead of the system default route, the SDK completely bypasses user-configured local VPN tunnels (tun0). - Broad Definition of "Idle": The SDK configuration allows relaying traffic even when the user is actively on a phone call or the screen is on, provided CPU utilization remains below 70% and memory below 90%.
- Cross-Platform Identity Stitching: The SDK's config file contains tracking properties like
dual_pairingmaps designed to tie a single user's distinct installations across iOS, Windows, and macOS together into a single unified identity. - Mitigation and Defense Strategies:
- DNS Sinkholing: Network-wide blocking of key domains (
proxyjs.brdtnet.com,proxyjs.luminatinet.com,proxyjs.bright-sdk.com, andclientsdk.bright-sdk.com) entirely kills the proxy peer tunnel without impacting legitimate public traffic. - Network Boundaries: Utilizing TLS SNI filtering on domains matching
*.brdtnet.comor*.luminatinet.com. - MDM Application Auditing: For enterprise environments, scanning mobile binaries for unique Swift symbols like
BrdWebSocketFacadeandBrdNetwork.DNSResolverto filter out infected applications.
- DNS Sinkholing: Network-wide blocking of key domains (
Hacker News Discussion
- The Irony of Cloud-to-Cloud Scrapes: Users point out the profound irony that both the AI data scrapers and the target websites being scraped are often simultaneously hosted on AWS infrastructures, engaging in a costly, artificial cat-and-mouse game to mask their identities.
- Strict Hardware Isolation ("Dumb" Displays): A popular consensus among commenters is to completely air-gap or isolate smart TVs from the internet, relying exclusively on local HDMI inputs connected to trusted devices (like Apple TV, HTPCs, or Home Assistant setups).
- Automatic Content Recognition (ACR) over HDMI: Contributors point out that simply removing network permissions may not protect privacy entirely if a TV is ever connected later. Academic papers cited in the thread reveal that Smart TVs run Automatic Content Recognition to analyze and log content even on local HDMI inputs while offline, caching data to upload the moment an internet connection becomes available.
- The Threat of VPN Bypassing: The community expressed severe alarm regarding the SDK's ability to explicitly bypass local system VPN configurations via forced network interface bindings, highlighting the growing complexity required to self-host secure, consumer-friendly networks.
- Legal Risks and Misleading Consent: Commenters note that the SDK text hides behind the guise of "downloading public data," masking that its true utility is to circumvent security blocks. There is also discussion regarding the liability risk for home residents if a malicious third party utilizes their residential IP address through these unregulated networks for illicit activities (e.g., severe cybercrimes), though others note Bright Data utilizes strict Know-Your-Customer (KYC) onboarding for their buyers.
- Network-Level Defense: Users shared practical setups for containment, such as creating isolated local VLANs with restrictive firewall configurations, whitelisting device MAC addresses via DHCP policies, and deploying Pi-holes or AdGuard Home setups to drop the domains mentioned in the report.
-
-
www.commonsensemedia.org www.commonsensemedia.org
-
Children cannot meaningfully consent to data collection, and parents often don't fully understand the extent of what's being collected. AI toys gather voice recordings, conversation transcripts, usage patterns (when, how long, and what topics), emotional tone analysis, behavioral data (what makes the child engage or disengage), and derived insights into development, interests, and emotional states.
这里描述的数据收集范围远超家长购买玩具时的想象。情感语气分析和行为参与模式本质上是对儿童的心理画像——生成关于发展脆弱性、情绪触发点和兴趣图谱的洞察,这些数据可能保存数十年,并在家长毫无有效救济手段的情况下被出售或泄露。COPPA正是为此而生,但执法速度远远落后于技术能力的发展。
-
- May 2026
-
www.bbc.com www.bbc.com
-
Trillions of miles of data: Your car is spying on you, and it's only just the beginning
- Evolution of Cars into Computers: Modern vehicles are now highly sophisticated computers on wheels that continuously harvest deeply intimate details of their drivers' lives to generate corporate revenue.
- Extensive Data Harvesting: Car manufacturers track data points that extend far beyond simple GPS routing. Collected data includes exact geographic location, passenger presence, radio selection, seatbelt usage, acceleration and braking behaviors, weight, age, race, and even facial expressions via internal cabin cameras.
- Monetization and Financial Risks: This data is regularly passed to or bought by insurance companies, who utilize driving behavior analytics to raise premium costs for consumers. Most car companies acknowledge selling this information, though they rarely name the specific buyers.
- Pervasive Market Penetration: According to consulting firm McKinsey, internet connectivity in households' vehicles reached 50% in 2021 and is projected to hit 95% by 2030, making telemetry tracking near-universal for modern drivers.
- Complete Privacy Failure: A rigorous 2023 evaluation by Mozilla scrutinized 25 major automotive brands and found that every single one failed to meet minimum privacy and security standards, officially labeling cars as the absolute worst product category ever reviewed for consumer privacy.
- Impending Federal Telematics Escalation: Upcoming US federal mandates will worsen the privacy landscape by requiring automakers to integrate infrared biometric cameras and behavioral scanners to catch drunk or fatigued drivers. However, there are no legal frameworks limiting how manufacturers can monetize or distribute this newly mandated health and biometric data.
Hacker News Discussion
- Two-Sided Surveillance Encroachment: Users point out that privacy is under attack from both inside the vehicle (internal cameras and telemetry) and outside the vehicle (omnipresent roadside cameras and license plate readers like Flock).
- Need for Broad Legislative Reform: There is a strong consensus that individual consumer choice is insufficient; legal frameworks must step in to strictly regulate all forms of data collection, third-party sharing, and camera placement without public consent.
- Pervasive Corporate Distopia: The discussion highlights a growing sense of exhaustion and resignation over 24/7 corporate tracking across all areas of life, comparing the sleepwalk into a corporate police-state to an inescapable reality.
- Hardware and Software Workarounds: Tech-savvy users discuss actively tampering with their vehicles to regain privacy, such as physically yanking out the integrated cellular modem boards or using specialized diagnostic software (like ForScan) to fully disable built-in telemetry features.
-
-
www.thecut.com www.thecut.com
-
Brooding: In 2026, I Resolve to Friction-Maxx<br /> by [[Kathryn Jezer-Morton]]<br /> accessed on 2026-05-12T10:31:16
read on 2026-05-28T17:02:02
-
-
www.anthropic.com www.anthropic.com
-
We don't train on your data by default on our Team and Enterprise Plans.
大多数人认为AI公司会默认使用用户数据进行模型训练以提高产品性能。但Anthropic明确表示默认情况下不会使用用户数据训练模型,这是一个与行业惯例相悖的做法,反映了他们对数据隐私的重视和对用户信任的承诺。
-
We don't train on your data by default on our Team and Enterprise Plans.
大多数人认为AI公司会默认使用用户数据进行模型训练以改进产品。但作者明确表示Anthropic不会默认使用客户数据进行训练,这挑战了AI行业普遍的数据收集和训练实践,是一个非共识的隐私立场。
-
-
www.thatprivacyguy.com www.thatprivacyguy.com
-
🔒【令人震惊】Chrome 在数十亿设备上静默写入 4GB Gemini Nano 模型权重,删除后自动重装,可能违反 GDPR。这是「端侧 AI」与用户隐私的第一次正面冲突——不是关于数据收集,而是关于在未经同意的情况下使用用户存储空间和计算资源。这个事件的先例意义巨大:如果 Google 可以这样做,所有内置 AI 的操作系统和浏览器都有可能效仿,用户对自己设备的控制权正在被悄悄侵蚀。
-
-
www.heise.de www.heise.de
-
Digital Sovereignty: Wire to Replace Signal as Standard in the Bundestag
- Bundestag Security Shift: Bundestag President Julia Klöckner has recommended that members of the German Parliament switch from Signal to "Wire," a BSI-certified messenger, as the new standard for communication.
- Digital Sovereignty: The move is framed as a step toward digital sovereignty, reducing reliance on US-based platforms like Signal or WhatsApp in favor of a service with European roots and German security certification.
- Phishing Mitigation: A primary driver for the recommendation is security; Wire allows registration via email rather than a phone number, which is intended to hide a central identification feature and make phishing attacks more difficult.
- BSI Certification: The "Wire Bund" version has been approved for data classified as "Verschlusssache – nur für den Dienstgebrauch" (Restricted) until 2028.
- Human Factor vs. Technology: Critics and experts note that while Wire is secure, it is not a "panacea." Recent successful phishing attacks against politicians (including Klöckner herself) highlight that the human user is often the weakest link, regardless of the app's encryption.
Hacker News Discussion
- Vendor Lock-in Irony: Commenters pointed out the irony of moving from one vendor-locked system (Signal/US) to another (Wire/German-Swiss), questioning why the government didn't choose Matrix, which is an open standard used by NATO and other EU entities.
- Deployment Details: A former developer shared that Wire was originally deployed for the Bundeskanzleramt using a Nix-based delivery method to allow for completely air-gapped server installations.
- Skepticism of Motivation: Some users suggested the switch might be politically motivated or a way for Klöckner to deflect from her own experience being phished, rather than a purely technical security upgrade.
- Data Privacy Concerns: Discussion arose regarding jurisdiction; while Signal is US-based, Wire is subject to German/Swiss law. This is seen as a benefit for EU sovereignty but also raises questions about local legal intercept requirements.
- Technical Comparisons: Users debated the UX and backup reliability of Wire versus Signal, with some noting that Wire's media backup system has historically been less robust than Signal's.
-
-
www.technologyreview.com www.technologyreview.com
-
“A lot of what we think of as privacy protection isn’t so much like something that’s written in the law,” says Karen Levy, a professor of information science at Cornell University.
这段话揭示了隐私保护的复杂性,并非仅仅是法律问题,而是涉及到获取数据的难易程度。
-
-
gizmodo.com gizmodo.com
-
According to a press release, users will be required to undergo World’s verification method, which requires having their eyeballs scanned at a physical location with a proprietary device to prove they are human.
This quote highlights a significant requirement for users, which may raise concerns about privacy and the feasibility of such a process.
-
- Apr 2026
-
developer.chrome.com developer.chrome.com
-
The network requirement is only for the initial download of the model. Subsequent use of the model does not require a network connection. No data is sent to Google or any third party when using the model.
大多数人认为使用Google的AI模型必然会涉及数据传输和隐私问题,但作者强调模型完全在设备上运行且不向Google发送数据。这与人们对大型科技公司AI服务通常涉及数据收集的普遍认知相悖,暗示Chrome的AI功能可能比想象的更加注重隐私保护。
-
-
buttondown.com buttondown.com
-
Impact of having doctor visit being transcribed by AI The GDPR issues aside, there is a strong indication that writing is the thinking for physicians but they might not realise that. - [ ] return #pkm
-
-
www.theregister.com www.theregister.com
-
Meta, the company built on watching everything its billions of users do online so it can keep them clicking on ragebait and targeted ads, is reportedly now installing surveillance software on employees’ work computers.
大多数人认为Meta公司会尊重用户隐私,但作者指出Meta现在在其员工的工作电脑上安装监控软件,这表明公司可能并不总是将用户隐私放在首位。
-
-
-
Some privacy related extensions may cause issues on x.com. Please disable them and try again.
这是一个令人惊讶的反讽:一个强调隐私保护的社交平台,却要求用户禁用隐私保护扩展才能正常访问,暗示平台商业利益与用户隐私保护之间存在根本冲突。
-
-
-
Some privacy related extensions may cause issues on x.com.
这一陈述暗示了隐私保护工具与主流平台功能之间存在根本冲突,反映了平台商业利益与用户隐私权之间的紧张关系。这揭示了一个令人不安的现实:追求隐私可能意味着牺牲数字参与度。
-
-
-
Some privacy related extensions may cause issues on x.com.
这句话暗示了隐私保护工具与主流社交平台之间的潜在冲突。这反映了数字隐私与平台商业利益之间的张力。用户安装隐私扩展通常是为了保护数据不被收集,但平台可能将这些工具视为干扰其数据收集和分析的障碍。这种冲突预示着未来网络环境中隐私保护与平台功能之间的持续博弈。
-
-
-
Some privacy related extensions may cause issues on x.com.
这句话暗示了隐私保护工具与主流网站服务之间的潜在冲突。这反映了数字时代的一个核心矛盾:用户想要保护自己的隐私,而平台则需要收集数据来提供个性化服务。这种冲突可能导致用户在隐私和便利性之间做出艰难选择。
-
-
-
Some privacy related extensions may cause issues on x.com. Please disable them and try again.
这一警告暗示了隐私保护工具与主流平台之间的根本冲突,反映了平台商业利益与用户隐私权之间的紧张关系。用户被迫在隐私和功能之间做出选择,这揭示了现代数字生态系统中用户权利被系统性削弱的令人担忧的趋势。
-
-
-
Some privacy related extensions may cause issues on x.com.
这一声明暗示了平台与用户隐私工具之间的潜在冲突,揭示了社交媒体平台可能对用户隐私保护工具的排斥态度。这引发了一个值得深思的问题:平台安全与用户隐私之间的界限在哪里?
-
-
-
Some privacy related extensions may cause issues on x.com.
这是一个令人惊讶的声明,暗示社交媒体平台可能主动阻止用户使用隐私保护工具。这可能表明X平台的数据收集策略与用户隐私保护之间存在根本冲突,值得深入研究其商业模式与用户权利的平衡问题。
Tags
Annotators
URL
-
-
-
Some privacy related extensions may cause issues on x.com.
这是一个令人深思的矛盾点:本应保护用户隐私的浏览器扩展反而可能导致平台功能失效。这暗示了X(前Twitter)的某些功能可能依赖于数据收集,与用户隐私保护存在根本性冲突,反映了数字服务中隐私与功能的持续博弈。
Tags
Annotators
URL
-
-
-
Some privacy related extensions may cause issues on x.com.
这一陈述暗示了隐私保护工具与主流平台之间的潜在冲突,揭示了平台方与用户隐私保护之间的紧张关系。这表明在当前互联网生态中,用户为保护隐私而采取的措施可能被平台视为'问题',反映了平台利益与用户隐私权之间的根本性矛盾。
-
-
-
Some privacy related extensions may cause issues on x.com. Please disable them and try again.
这个声明揭示了平台与用户隐私工具之间的紧张关系,暗示X(推特)可能故意限制隐私功能以收集更多数据,这种商业利益与用户隐私的冲突是当今数字平台的核心矛盾之一。
-
-
-
Some privacy related extensions may cause issues on x.com.
这句话暗示了一个令人深思的悖论:用户安装隐私保护工具(如广告拦截器、隐私增强扩展)来保护自己的数据,但这些工具反而可能阻止他们访问平台。这揭示了平台利益与用户隐私保护之间的冲突,以及现代互联网服务对用户数据的依赖程度。
-
-
github.com github.com
-
Sage sends URLs and package hashes to Gen Digital reputation APIs. File content, commands, and source code stay local.
这个隐私声明揭示了Sage的数据处理策略,采用了最小化数据传输的设计哲学。这种平衡安全与隐私的做法很有洞察力,表明开发者理解用户对数据泄露的担忧,同时认识到某些云端分析对于有效威胁检测的必要性。
-
Sage sends URLs and package hashes to Gen Digital reputation APIs. File content, commands, and source code stay local.
令人惊讶的是:Sage 采用了一种平衡隐私和安全的方法,只将URL和包哈希发送到云端进行声誉检查,而文件内容、命令和源代码则保留在本地。这种设计既提供了实时的威胁检测,又保护了用户的敏感数据,反映了现代安全工具对隐私保护的重视。
-
-
-
Closed harnesses behind proprietary APIs force yielding control of agent memory to third parties.
令人惊讶的是:专有API背后的封闭式代理工具迫使用户将代理记忆的控制权让渡给第三方。这意味着用户在使用AI代理时可能不知不觉地失去了对自己数据和个人信息的控制权,这可能引发严重的隐私和安全问题。
-
-
www.wired.com www.wired.com
-
Illinois was also early to regulate biometric data collection, passing the Biometric Information Privacy Act in 2008.
令人惊讶的是:伊利诺伊州在2008年就通过了生物特征信息隐私法,比许多州的AI监管立法早了近15年。这表明该州在技术监管方面一直处于前沿,从生物识别数据到AI,该州似乎总是提前应对新兴技术带来的隐私挑战。
-
-
chatgpt.com chatgpt.com
-
The ChatGPT for Excel add-in operates separately from your ChatGPT chat history. Conversations and data in Excel aren't shared with your ChatGPT chats, and activity doesn't sync between experiences at this time.
令人惊讶的是:Excel中的ChatGPT功能与普通聊天历史是完全隔离的,两个系统之间没有数据同步。这意味着用户可以在Excel中使用AI处理敏感数据,而不用担心这些信息会出现在他们的常规聊天记录中,提供了额外的隐私保护层。
-
By default, data shared with ChatGPT isn't used to improve our models for ChatGPT Business, ChatGPT Enterprise, ChatGPT Edu, and ChatGPT for Teachers.
令人惊讶的是:企业级用户的Excel数据默认不会被用于训练AI模型,这与普通用户的数据处理方式有显著区别。这种差异反映了OpenAI对商业客户隐私的特别保护,可能是为了增强企业采用AI工具的信心。
-
-
9to5mac.com 9to5mac.com
-
Messages were recovered from Sharp's phone through Apple's internal notification storage—Signal had been removed, but incoming notifications were preserved in internal memory.
令人惊讶的是:即使Signal应用被从iPhone上删除,苹果设备的内部通知存储系统仍然保留了收到的消息内容。这表明iOS系统在应用删除后仍会缓存通知数据,这可能成为执法机构获取已删除消息的意外途径,而大多数用户并不意识到这一潜在的数据泄露风险。
-
-
-
Priority areas include safety evaluation, ethics, robustness, scalable mitigations, privacy-preserving safety methods, agentic oversight, and high-severity misuse domains.
大多数人认为AI安全研究主要集中在防止恶意使用和确保系统对齐人类价值观上。但作者将隐私保护方法列为优先领域,这表明OpenAI正在将隐私视为安全的核心组成部分,而非一个独立考虑的因素,这与传统上将隐私和安全视为两个不同领域的观点相悖。
-
- Feb 2026
-
thelocalstack.eu thelocalstack.eu
-
I Verified My LinkedIn Identity. Here's What I Actually Handed Over.
- The author investigated the privacy implications of LinkedIn's "Identity Verification" badge, which is handled by a third-party provider called Persona.
- To verify, users must provide a government ID, a live "selfie" (biometric scan), and access to NFC data on their passport.
- Upon examining the legal disclosures, the author found that data is shared with a surprisingly long list of 17 subprocessors.
- Notable subprocessors listed include OpenAI, Anthropic, and Groqcloud, raising concerns about biometric and personal data being used for AI training.
- The privacy policy cites "Legitimate Interest" as the legal basis for processing, which the author suggests is a way to bypass explicit consent for data sharing.
- The article concludes that the perceived value of a "verified" checkmark on a professional profile does not outweigh the significant privacy risks and the distribution of sensitive biometric data to numerous tech corporations.
Hacker News Discussion
- A top comment notes that Persona’s CEO responded to the claims, asserting that no personal data is used for AI training and that biometric data is deleted immediately after processing.
- The CEO claimed the full list of subprocessors is a "catch-all" for all their services (like background checks), and only 8 subprocessors are actually used for the identity verification product specifically.
- Many users remained skeptical of the "catch-all" explanation, arguing that if a company is sure about privacy, they should explicitly limit the legal language rather than using broad "CYA" (Cover Your Assets) terms.
- Commenters discussed the inherent risks of "Know Your Customer" (KYC) processes, noting that even if data is deleted, the initial collection creates a honeypot for potential breaches.
- Some participants argued that the "Legitimate Interest" justification is often abused in the EU to avoid the stricter requirements of explicit consent under GDPR.
- There was a general consensus among technical users that a social media badge is insufficient justification for handing over highly sensitive, unchangeable biometric markers.
-
-
blog.dmcc.io blog.dmcc.io
-
What Your Bluetooth Devices Reveal About You
- Project Overview: The author developed "Bluehood," a Python-based Bluetooth scanner, to demonstrate the extensive metadata leaked by devices merely by having Bluetooth enabled.
- Motivation: Triggered by a critical vulnerability (WhisperPair CVE-2025-36911) and a desire to visualize invisible digital footprints, the project highlights how "invisible" signals compromise privacy.
- What Bluetooth Reveals About Users: By monitoring signals passively, the author could determine:
- Delivery Logistics: Exact arrival times of delivery vehicles and whether the same driver visits repeatedly.
- Daily Routines: The specific daily patterns of neighbors based on their phone and wearable broadcasts.
- Device Associations: Which devices belong to the same person (e.g., a specific phone moving in tandem with a specific smartwatch).
- Occupancy & Location: Exact times people are home, at work, or elsewhere.
- Security Vulnerabilities: Periods when a house is typically empty.
- Social Patterns: Regular visitors (e.g., someone visiting every Thursday afternoon).
- Employment Indicators: Patterns that suggest specific work types, such as shift work.
- Family Schedules: Specific times children return home from school.
- Consumer Habits: Which households share the same delivery drivers, implying similar shopping preferences.
- Incident Evidence: Retrospective logs of who was present (passersby, dog walkers) during specific events like property damage.
- Uncontrollable Broadcasts:
- Many devices broadcast continuously without user recourse, including medical implants (pacemakers, hearing aids), modern vehicles, and smart home tech.
- Privacy tools like Briar or BitChat require Bluetooth for off-grid mesh networking, creating a paradox where privacy tools necessitate privacy leaks.
- Technical Functionality:
- Bluehood uses passive scanning to identify vendors and device types without connecting.
- It analyzes patterns (heatmaps, dwell times) and filters out randomized MAC addresses to focus on persistent tracking.
Hacker News Discussion
- Ubiquitous Tracking: Commenters confirmed that similar tracking is common in retail (using iBeacons to track shoppers to specific shelves) and via vehicle sensors (TPMS in tires broadcasting unique IDs).
- WiFi vs. Bluetooth: Users noted that WiFi signals from cars (often named "Audi", "Tesla", etc.) are just as leaky as Bluetooth, allowing for easy "wardriving" profiles.
- Medical Privacy: Significant concern was raised regarding medical devices (like CPAP machines) that broadcast 24/7, often to satisfy insurance requirements, with no way for the patient to disable the radio.
- Mitigation Strategies:
- OS Features: GrapheneOS and recent Android versions offer settings to automatically turn off Bluetooth after a period of inactivity.
- iOS Limitations: Apple users noted it is harder to keep Bluetooth permanently off without diving into settings or using Shortcuts, as the Control Center toggles are temporary.
- Legal Context: Several users pointed out that while such tracking is rampant in some regions, it is strictly regulated or forbidden in the EU without explicit consent.
-
- Jan 2026
-
www.eleanorkonik.com www.eleanorkonik.com
-
As for the privacy concerns? There isn’t anything private in my vault, so I don’t really care about Anthropic access.
if you don't have personal stuff or personal data on others in your vault, privacy is less a concern with cloud models. True. Except I think any pkm is about personal knowledge and while not personal data per se, there is a vulnerability involved there.
-
-
techcrunch.com techcrunch.com
-
Microsoft gave FBI a set of BitLocker encryption keys to unlock suspects’ laptops: Reports
- Microsoft provided the FBI with BitLocker recovery keys for three laptops seized in a fraud investigation related to Guam's Pandemic Unemployment Assistance program.
- BitLocker, Windows' full-disk encryption enabled by default, uploads recovery keys to Microsoft's cloud by default, allowing access by Microsoft and law enforcement with a warrant.
- Microsoft receives about 20 such requests per year and complies; a spokesperson did not comment for TechCrunch.
- Cryptography expert Matthew Green criticized Microsoft for not securing keys better, noting repeated cloud breaches and industry lag.
- Risks include hackers compromising Microsoft's cloud to steal keys (requiring physical drive access) and privacy concerns from key escrow.
Hacker News Discussion
- Users debate defaults: reasonable for average users to protect against theft while allowing recovery, but power users should avoid cloud upload using local accounts.
- Complaints about Microsoft pushing Microsoft accounts, auto-uploading data (e.g., via Teams, Edge), and difficulty opting out without re-encrypting.
- Comparisons to Apple FileVault/iCloud: Apple prompts choice and uses E2EE keychain; Microsoft criticized for sneaky behavior and lacking clear warnings.
- Suggestions to switch to Linux for privacy; distrust in Microsoft due to ads, updates overriding settings, and potential key upload even when opted out.
- Broader concerns: warrants compel compliance, but better design (no key collection) prevents issues; cosmic ray bit-flips or bugs could accidentally upload keys.
-
-
www.consentmanager.net www.consentmanager.net
- Dec 2025
-
troubled.engineer troubled.engineer
-
How I block all online ads
- The author describes a comprehensive setup to block virtually all online advertising across devices and services.
- They focus on network-level filtering instead of per-device ad blockers, so that phones, TVs, and other clients benefit automatically.
- The core of the solution is running a self-hosted DNS-based blocker (like Pi-hole or AdGuard Home) to sinkhole common ad and tracker domains.
- Additional blocklists are layered on top to handle more aggressive tracking and region-specific ad domains, trading a bit of breakage for increased privacy.
- For services that hardcode ad endpoints or use techniques that bypass DNS blocking, the author uses more advanced tools such as proxying or firewall rules.
- Some apps and sites break when ads are blocked; in those cases, the author selectively whitelists domains or uses per-device exceptions rather than relaxing global rules.
- On mobile, encrypted DNS and VPN-like tunneling are configured so that all traffic still flows through the home-level blocking setup even on the go.
- The author argues that this configuration significantly improves page load times, reduces bandwidth usage, and makes devices feel faster and less cluttered.
- They acknowledge an ethical gray area with ad blocking but conclude that user safety, privacy, and mental comfort outweigh the downsides of depriving low-quality ad networks of revenue.
- The piece emphasizes that the goal is not absolute perfection but a sustainable setup that requires minimal maintenance once deployed.
Hacker News Discussion
- Commenters discuss additional tools like SponsorBlock for skipping in-video sponsorships on platforms such as YouTube, highlighting that traditional ad blockers do not remove creator-embedded promos.
- Several users point out that DNS-level blocking does not stop ads injected directly by streaming services, noting that such platforms often use certificate pinning or app-level tricks that make proxying and MITM approaches difficult or impossible.
- A highly upvoted comment recommends using a user-agent switcher to bypass sites that block non-Chrome browsers, with examples where services claim to be incompatible with Firefox but run better once the browser “pretends” to be Chrome.
- Participants criticize websites that enforce brittle user-agent checks instead of feature detection, arguing that this needlessly breaks otherwise compatible browsers and punishes privacy-conscious users.
- Some users express skepticism about privacy-focused browsers that are built on or dependent on codebases controlled by ad-driven companies, calling out an inherent tension between privacy promises and ad-based business models.
Tags
Annotators
URL
-
- Nov 2025
-
blog.calebjay.com blog.calebjay.com
-
Don't Download Apps
- Companies aggressively push app downloads, especially in places like Taiwan, offering discounts but often installing without full consent, leading to spam and unwanted data collection.
- Avoid handing over your phone to staff and never download apps, as they provide minimal benefits compared to the risks involved.
- Primary risks include surveillance capitalism: apps enable extensive data tracking for targeted ads and "surveillance pricing," where prices vary based on inferred financial status (e.g., charging more after payday).
- This undermines fair pricing, giving corporations power over individual costs beyond market forces.
- Apps enforce binding arbitration clauses in Terms of Service, waiving rights to court, jury trials, or oversight; examples include Disney attempting to force arbitration in a wrongful death case linked to a Disney+ trial.
- Predictions highlight future abuses, like arbitration forced via unrelated services (e.g., Uber Eats leading to self-driving car disputes).
- Recommendation: Use websites or PWAs instead to preserve privacy and rights.
Hacker News Discussion
- Users debate apps vs. websites/PWAs: many praise PWAs (e.g., Mastodon, Photoprism) for performance when implemented well, criticizing poor web apps and noting apps often wrap webviews with extra tracking.
- Privacy concerns dominate: native apps access more device data (contacts, SMS, biometrics, etc.) even with permissions, unlike sandboxed PWAs; tools like NetGuard suggested for blocking app internet access.
- Loyalty discounts viewed as modern coupons by some, saving money despite data sharing, but others warn of surveillance pricing via purchase patterns and arbitration risks.
- Experiences shared: retailers reject Apple Pay to force accounts; global pushiness for apps noted; arbitrage limits price discrimination viability.
- Calls for better OS controls, open-source apps without tracking, and skepticism of app store security.
Tags
Annotators
URL
-
-
www.reddit.com www.reddit.com
-
brozelam • 1y ago My phone number has been on the national so not call list since 2007. That means any call from anyone with whom I do not have direct, prior relationship where I specifically and expressly gave permission to contact me has run a foul of both federal TCPA and my state's law, combined. After some trial and error, I have Cube ACR app running on my Android phone to record every phone call. I take the call, act interested enough to get their information, keep notes and logs. Usually I would give them a made up email to my own domain(s) so I can see who else they sell my information to as well. I also have a dummy bank account with debit card and like $1 in it if they ask for it. Once I get them to email me, or am able to verify who the caller is, including by putting up with their entire sales pitch, I tell them to put me on the do not call list and I hang up. It's in their best interest not to call back but I already have cause for suing them. Most of them are stupid and will recycle you back and call again over and over. Especially if you tick them off they'll revenge dial you. I've had actual law firms pushing covid relief funds angry call me after I keep them on the phone with bulllshit interest and then sys no thanks. Paid Cube ACR allows you to make notes so I note who it was. So I just kept notes with the name of the end caller since they usually call through call centers in India, typically. The first defendant called 8 times after I told them to stop and put me on their do not call list. Their call center agent heard the call recorder warning when I accidentally mashed a number and called back to threaten me. That was an hour after I told them I'm not interested and to stop. Altogether they had call me 4 times in 4 hours. If they call back it usually means they do not have a do not call list even though the FCC requires it. That alone is something like $44,000 fine by the government and I use as leverage to settle and extract info on who is selling and reselling my information. I would give them fake names with a specific spelling, month later someone else calls and uses that exact name. In my state I get $5000 for 3rd and subsequent calls for each violation of statues so - calling after do not call request, obfuscating their real identity/number, failure to maintain dnc, list and procedures etc each one is a separate fine I am entitled to by state statute and able to collect. Including attorneys fees. My case was solid enough for lawyers to take on so I went that route. Lawyers usually won't go for single call violations but you can drag a caller to small claims court however, in your own state, even for 1 call if they refuse to settle and you have your evidence lined up and it's solid - the call recording, emails from them, etc. A typical call will be worth around $5000 depending on your state laws too. All fines for the violations are about $1500 each for violation federal law so it adds up. I'm typing this from my phone but if there's something you have a question about feel free to ask
-
- Oct 2025
- Jun 2025
-
zenodo.org zenodo.orgPreview1
-
Yoose, B., & Shockey, N. (2024). Navigating Risk in Vendor Data Privacy Practices: An Analysis of Springer Nature's SpringerLink (Version v1). SPARC. https://doi.org/10.5281/zenodo.13886473
Abstract
Navigating Risk in Vendor Data Privacy Practices: An Analysis of Springer Nature's SpringerLink documents a variety of practices that undermine library privacy standards. SpringerLink provides a case study in the encroachment of the broader surveillance-based data brokering economy into academic systems. Combined with our 2023 report on Elsevier’s ScienceDirect platform, this analysis illustrates the wide range of privacy risks inherent in the business models and practices in the academic scholarship marketplace.
Among other findings, the report documents risks related to the 200 named third parties that are allowed to collect information from users of the site (along with what appear to be additional unlisted companies found only in our public website analysis). While the specific privacy concerns posed by SpringerLink are different, our analysis reiterates the findings from our ScienceDirect report: that user tracking that would be unthinkable in a physical library setting now happens routinely through publisher platforms.
While this analysis and recommended actions are grounded in the library context, these findings will raise pressing issues for faculty, administrators, and policymakers to consider as well. The report closes with suggested actions that libraries can take over both the short and long term to address vendor privacy risks.
-
-
www.bose.com www.bose.com
-
Public forums Certain features of our Services make it possible for you to post comments, photos, or other content publicly with other users, such as a Bose forum or a social networking site. Any information that you submit through these features is not confidential, and Bose may use it for any purpose (including in testimonials or other marketing materials). For example, if you submit a product review on one of our sites, we may display your review (along with the name you provide, if any) on other Bose websites, and on third-party websites. Any information you post openly in these ways will be available to the public at large and potentially accessible through third-party search engines. Accordingly, please take care when using these features.
Taken to its extreme, this seems to suggest that Bose can use anything you post on Facebook as part of its marketing materials.
-
environmental data (e.g., noise levels and audio frequencies of sounds around you).
This sounds like Bose can listen to conversations happening around you (if they so choose).
-
Information about the services and content you access via your Bose product or software, such as media, external sources, and third-party services you connect to your Bose product or software, user IDs service tokens that allow you to access and sync to your third-party accounts, and content accessed via your product or software (e.g., sleep tracks, stations, playlists, artists, albums, songs, or podcasts).
By agreeing to this privacy policy, you are essentially letting Bose know everything you watch and listen to.
-
- Apr 2025
-
www.inkandswitch.com www.inkandswitch.com
-
Detailed Summary
1. You own your data, in spite of the cloud. <br /> Section summary: <br /> Local-fist software tries to solve the problem of ownership, agency and data lock-in present in cloud-based software, without compromising cross-collaboration and improving user control.
Section breakdown<br /> §1: SaaS<br /> Pros: Easy sync across devices, real-time collab Cons: loss of ownership and agency; loss of data is software is lost.
§2: Local-fist software<br /> - Enables collaboration & ownership - Offline cross-collaboration - Improved security, privacy, long-term preservation & user control of data
§3 & §4: Article Methodology<br /> - Survey of existing storage & sharing approaches and their trade-offs - Conflict-free Replicated Data Types (CRDTs), natively multi-user - Analysis of challenges of the data model as implemented at Ink & Switch - Analysis of CRDT viability, UI - Suggestion of next steps
2. Motivation: collaboration and ownership<br /> Section summary: <br /> The argument for cross-device, real-time collab PLUS personal ownership
Section breakdown<br /> §1: Examples of online collabs<br /> §2: SaaS increasingly critical, data increasingly valuable<br /> §3: There are cons<br /> §4: Deep emotional attachment to your data brings feeling of ownership, especially for creative expression<br /> §5: SaaS require access to 3rd party server, limitation on what can be done. Cloud provider owns the data.<br /> §6: SaaS: no service, no data. If service is shut down, you might manage to export data, but you may not be able to run your copy of the software.<br /> §7: Old-fashioned apps were local-disk based (IDEs, git, CAD). You can archive, backup, access or do whatever with the data without 3rd party approval.<br /> §8: Can we have collaboration AND ownership?<br /> §9: Desire: cross-device, real-time collab PLUS personal ownership
3. Seven ideals for local-first software<br /> Section breakdown<br /> §1: Belief: data ownership & real-time collab are compatible<br /> §2: Local-first software local storage & local networks are primary, server secondary<br /> §3: SaaS: In the server, or it didn't happen. Local-first: local is authoritative, servers are for cross-device.
3.1.1 No spinners<br /> SaaS feels slower because if requires round-trip to a server for data modification and some lookups. Lo-Fi doesn't have dependency on server, data sync happens on the background. This is no guarantee of fast software, but there's a potential for near-instant response.<br /> 3.1.2 Data not trapped on one device <br /> Data sync will be discussed in another section. Server works as off-site backup. The issue of conflict will also be discussed later.<br /> 3.1.3 The network is optional<br /> It's difficult to retrofit offline support to SaaS. Lo-Fi allows CRUD offline and data sync might not require the Internet: Bluetooth/local Wi-fi could be enough.<br /> 3.1.4 Seamless collabs<br /> Conflicts can be tricky for complex file formats. Google Docs became de facto standard. This is the biggest challenge for Lo-Fi, but is believed to be possible. It's also expected that Lo-Fi supports multiple collab.
TBC
Tags
Annotators
URL
-
- Mar 2025
-
www.theguardian.com www.theguardian.com
Tags
- Dakota access pipeline
- International Center for Not-for-Profit Law
- 2025-03-21
- Greenpeace
- ACLU’s Speech, Privacy, and Technology Project,
- Slapp suits
- Brian Hauss
- by: Rachel Leingang
- Waniya Locke
- USA
- Sushma Raman
- Energy Transfer
- Amnesty International
- event: ruling against Greenpeace in North Dakota 2025-03-19
- Michael Gerrard
- Standing Rock Grassroots
- Sabin Center for Climate Change Law at Columbia Law School
Annotators
URL
-
www.techradar.com www.techradar.com
-
The analysis uncovered an average of 11 different types of data out of the 35 possible. As mentioned earlier, Google Gemini stands out as the most data-hungry service, collecting 22 of these data types, including highly sensitive data like precise location, user content, the device's contacts list, browsing history, and more.Among the analyzed applications, only Google Gemini, Copilot, and Perplexity were found to collect precise location data. The controversial DeepSeek chatbot stands right in the middle, collecting 11 unique types of data, such as user input like chat history.
-
-
media.dltj.org media.dltj.org
-
by Erik Rye, Researcher, University of Maryland
Wi-Fi Positioning Systems are used by modern mobile operating systems to geolocate themselves without the use of GPS. Both Google and Apple, for instance, run Wi-Fi Positioning Systems for Android and iOS devices to obtain their own location using nearby Wi-Fi access points as landmarks.
In this work, we show that Apple's Wi-Fi Positioning System represents a global threat to the privacy of hundreds of millions of people. When iOS devices need to geolocate themselves using nearby Wi-Fi landmarks, they transmit a list of hardware identifiers to Apple and receive the geolocations of those access points in return. Unfortunately, this process can be replicated by an unprivileged adversary, who can recreate a copy of Apple's Wi-Fi geolocation database by requesting the locations of access points around the world with no prior knowledge.
To make matters worse, we demonstrate that by repeatedly querying Apple's Wi-Fi Positioning System for the same identifiers, we can detect Wi-Fi router movement over time. In our data, we see evidence of home relocations, family vacations, and the aftermath of natural disasters like the 2023 Maui wildfires. More disturbingly, we also observe troop and refugee movements into and out of the Ukraine war and the impact of the war in Gaza.
We conclude by detailing our efforts at responsible disclosure, and offer a number of suggestions for limiting Wi-Fi Positioning Systems' effects on user privacy in the future.
-
- Feb 2025
-
a.wholelottanothing.org a.wholelottanothing.org
-
Kein How-to-Guide, sondern eine kurze Beschreibung der Besonderheiten von Signal für technisch weniger bewanderte Nutzerinnen und Nutzer. Bevor ich dieses Blogpost gelesen hatte, wusste ich nicht, dass Signal (die Stiftung, die für die Software und Hardware des Dienstes verantwortlich ist) nicht einmal Daten über Teilnehmer:innen an Chats und Gruppenchats entschlüsseln kann. Der Service weigert sich also nicht nur Metadaten über Kommunikation herauszugeben, es kann es gar nicht.
Es wirkt vielleicht paranoid, die eigene Kommunikation vor jeder möglichen Einsichtnahme schützen zu wollen. Aber angesichts von autoritären Politiker:innen, die im Bündnis mit monopolistischen Digitalkonzernen handeln, ist es wichtig ist, an alle Eventualitäten zu denken. Außerdem machen sich, wenn solche Techniken nicht massenhaft verwendet werden. genau die Leute verdächtig, die vor allem Verfolgung befürchten müssen.
Ich selbst verwende Signal auf meinem Mobiltelefon mit /e/OS, also einem weitgehend „Google-freien“, auf Datenschutz ausgerichteten Android. Ich lade die App von einem Repository für Open Source Software (F-Droid mit dem Guardian Project-Repository), also nicht von Google Play. Trotzdem bin ich nicht ganz sicher, dass meine Kommunikation über Signal nicht beobachtet werden kann. Mit rein technischen Mitteln lässt sich Sicherheit nicht herstellen, weil man die Möglichkeiten in Kommunikation einzudringen nicht alle voraussehen und ausschließen kann. Ein Restrisiko bleibt, aber ich versuche es so klein wie möglich zu halten.
-
- Jan 2025
-
blog.mozilla.org blog.mozilla.org
-
We believe the bill unduly dictates one particular technical approach, and does so without considering the privacy, security, and equity risks it poses.
unduly dictates one particular technical approach
-
-
attachments.are.na attachments.are.na
-
a more completelearner profile
more complete: for who? by what means? what implications?
-
“Collect it all” is a phrase used to encapsulate the mission of General Keith Alexander, director of the US National Security Agency
cf matters of disclosure, consent, and differing orientation to/with privacy: MIT Tech Review article on CMU Mites in TCS Hall
-
- Dec 2024
-
en.wikipedia.org en.wikipedia.org
-
Here's what ChatGPT shown me as summary of their Privacy policy: Analytics and Third-Party Services They use third-party analytics tools (e.g., Google Analytics) to understand how users interact with their services. These tools may collect anonymized or aggregated data, such as IP addresses or browsing behavior, but not personally identifiable information unless you've explicitly consented. Cookies and Tracking: Their cookies track usage patterns on their platform, which could include data about visited pages, clicks, or time spent on the site. However, this data is anonymized unless tied to your account or explicitly authorized.
^^ let's just trust em, right? or no? Ping me if that ended up being a no-no as I decide to continue using the app.
-
-
substack.com substack.com
-
You have the right to opt out of the sale of your Personal Information and the sharing of your Personal Information for the purpose of cross-context behavioral advertising.
-
- Sep 2024
-
www.youtube.com www.youtube.com
-
www.youtube.com www.youtube.com
-
for - Indyweb dev - vulnerabilities of software designed with centralized privacy
-
-
link.springer.com link.springer.com
-
Privacy principle
for - definition - privacy principle - quantum informational panpsyichism theory of consciousness - Federico Faggin - Giacomo Mauro D'Airiano
definition - privacy principle - experience isnot shareable, even in principle
-
- Jul 2024
-
archive.ph archive.ph
-
First, the complexity of modern federal criminal law, codified in several thousand sections of the United States Code and the virtually infinite variety of factual circumstances that might trigger an investigation into a possible violation of the law, make it difficult for anyone to know, in advance, just when a particular set of statements might later appear (to a prosecutor) to be relevant to some such investigation.
If the federal government had access to every email you’ve ever written and every phone call you’ve ever made, it’s almost certain that they could find something you’ve done which violates a provision in the 27,000 pages of federal statues or 10,000 administrative regulations. You probably do have something to hide, you just don’t know it yet.
-
- Jun 2024
-
-
People haven’t really come to grips with the fact that it’s not just personal privacy that matters, it’s also institutional privacy
-
- May 2024
-
media.dltj.org media.dltj.org
-
So I'm not surprised, and perhaps the last question about user privacy.
Question about the privacy of the user interacting with the RAG
It doesn't seem like JSTOR has thought about this thoroughly. In the beta there is kind of an expectation that the service is being validated so what users are doing is being watched closer.
-
- Apr 2024
-
arxiv.org arxiv.org
-
Privacy is realized by the group founder creating a specialkeypair for the group and secretly sharing the private group key with every new group member.When a member is removed from a group or leaves it, the founder has to renew the group’s keypair
Have locks on data is a nice idea.
But given we have dissemination/disclosure among friends only, do we need to encrypt the blocks? Given communication channels are encrypted.
-
-
-
stricter requirements
This is why Compuverse only collects name, business email and phone number.
-
-
www.ramotion.com www.ramotion.com
-
What are some top UX design principles when designing for kids?Some important UX design principles when designing for kids are as follows. Simplicity and clarity Interactive and engaging elements Age-appropriate content Safety and privacy Consistent feedback and rewards
There's 5 in this list and there was 4 in the other - I think Safety and Privacy is the one additional but it's also in my proposal because I am concerned about it too.
-
- Mar 2024
-
media.dltj.org media.dltj.org
-
Millions of Patient Records at Risk: The Perils of Legacy Protocols
Sina Yazdanmehr | Senior IT Security Consultant, Aplite GmbH Ibrahim Akkulak | Senior IT Security Consultant, Aplite GmbH Date: Wednesday, December 6, 2023
Abstract
Currently, a concerning situation is unfolding online: a large amount of personal information and medical records belonging to patients is scattered across the internet. Our internet-wide research on DICOM, the decade-old standard protocol for medical imaging, has revealed a distressing fact – Many medical institutions have unintentionally made the private data and medical histories of millions of patients accessible to the vast realm of the internet.
Medical imaging encompasses a range of techniques such as X-Rays, CT scans, and MRIs, used to visualize internal body structures, with DICOM serving as the standard protocol for storing and transmitting these images. The security problems with DICOM are connected to using legacy protocols on the internet as industries strive to align with the transition towards Cloud-based solutions.
This talk will explain the security shortcomings of DICOM when it is exposed online and provide insights from our internet-wide research. We'll show how hackers can easily find, access, and exploit the exposed DICOM endpoints, extract all patients' data, and even alter medical records. Additionally, we'll explain how we were able to bypass DICOM security controls by gathering information from the statements provided by vendors and service providers regarding their adherence to DICOM standards.
We'll conclude by providing practical recommendations for medical institutions, healthcare providers, and medical engineers to mitigate these security issues and safeguard patients' data.
-
-
www.ekransystem.com www.ekransystem.com
-
Striking a balance between data anonymization and data utility is crucial yet very challenging.
-
-
www.reuters.com www.reuters.com
-
Critics say this amounts to users having to pay for their privacy.
"If you aren't paying for it, you're the product."
"If you pay for it, you're paying for fundamental rights."
-
-
privacybot.io privacybot.io
Tags
Annotators
URL
-
- Feb 2024
-
academic.oup.com academic.oup.com
-
Harold Abelson, Ross Anderson, Steven M Bellovin, Josh Benaloh, Matt Blaze, Jon Callas, Whitfield Diffie, Susan Landau, Peter G Neumann, Ronald L Rivest, Jeffrey I Schiller, Bruce Schneier, Vanessa Teague, Carmela Troncoso, Bugs in our pockets: the risks of client-side scanning, Journal of Cybersecurity, Volume 10, Issue 1, 2024, tyad020, https://doi.org/10.1093/cybsec/tyad020
Abstract
Our increasing reliance on digital technology for personal, economic, and government affairs has made it essential to secure the communications and devices of private citizens, businesses, and governments. This has led to pervasive use of cryptography across society. Despite its evident advantages, law enforcement and national security agencies have argued that the spread of cryptography has hindered access to evidence and intelligence. Some in industry and government now advocate a new technology to access targeted data: client-side scanning (CSS). Instead of weakening encryption or providing law enforcement with backdoor keys to decrypt communications, CSS would enable on-device analysis of data in the clear. If targeted information were detected, its existence and, potentially, its source would be revealed to the agencies; otherwise, little or no information would leave the client device. Its proponents claim that CSS is a solution to the encryption versus public safety debate: it offers privacy—in the sense of unimpeded end-to-end encryption—and the ability to successfully investigate serious crime. In this paper, we argue that CSS neither guarantees efficacious crime prevention nor prevents surveillance. Indeed, the effect is the opposite. CSS by its nature creates serious security and privacy risks for all society, while the assistance it can provide for law enforcement is at best problematic. There are multiple ways in which CSS can fail, can be evaded, and can be abused.
Right off the bat, these authors are highly experienced and plugged into what is happening with technology.
-
- Jan 2024
-
-
Also just by observing what they’re doing it becomes pretty clear. For example: Facebook recently purchased full-page ads on major newspapers entirely dedicated to “denounce” Apple. Why? Because Apple has built a system-level feature on iPhones that allows users to very easily disable every kind of advertising tracking and profiling. Facebook absolutely relies on being able to track you and profile your interests, so they immediately cooked up some cynical reasons why Apple shouldn’t be allowed to do this.But the truth is: if Facebook is fighting against someone on privacy matters, that someone is probably doing the right thing.
-
- Nov 2023
-
developers.google.com developers.google.com
-
To improve user privacy, display moment notifications are intentionally delayed a random amount of time when FedCM is enabled.
How does that improve privacy?
-
- Oct 2023
-
www.youtube.com www.youtube.com
-
"Without the right to tinker and explore, we risk becoming enslaved by technology; and the more we exercise the right to hack, the harder it will be to take that right away" - Andre "Bunnie" Huang
hah, we are already "enslaved by technology". ask Ted Kaczynski
our enemies already have hardware backdoors, compromising emissions (tempest), closed-source firmware/drivers/hardware, ... but sure, "feel free"
Tags
Annotators
URL
-
-
code.visualstudio.com code.visualstudio.com
-
firefox-source-docs.mozilla.org firefox-source-docs.mozilla.org
-
``` { version: 4,
info: { reason: <string>, // what triggered this ping: "saved-session", "environment-change", "shutdown", ... revision: <string>, // the Histograms.json revision timezoneOffset: <integer>, // time-zone offset from UTC, in minutes, for the current locale previousBuildId: <string>, // null if this is the first run, or the previous build ID is unknown
sessionId: <uuid>, // random session id, shared by subsessions subsessionId: <uuid>, // random subsession id previousSessionId: <uuid>, // session id of the previous session, null on first run. previousSubsessionId: <uuid>, // subsession id of the previous subsession (even if it was in a different session), // null on first run. subsessionCounter: <unsigned integer>, // the running no. of this subsession since the start of the browser session profileSubsessionCounter: <unsigned integer>, // the running no. of all subsessions for the whole profile life time sessionStartDate: <ISO date>, // hourly precision, ISO date in local time subsessionStartDate: <ISO date>, // hourly precision, ISO date in local time sessionLength: <integer>, // the session length until now in seconds, monotonic subsessionLength: <integer>, // the subsession length in seconds, monotonic addons: <string>, // obsolete, use ``environment.addons``},
processes: {...}, simpleMeasurements: {...},
// The following properties may all be null if we fail to collect them. histograms: {...}, keyedHistograms: {...}, chromeHangs: {...}, // removed in firefox 62 threadHangStats: [...], // obsolete in firefox 57, use the 'bhr' ping log: [...], // obsolete in firefox 61, use Event Telemetry or Scalars gc: {...}, fileIOReports: {...}, lateWrites: {...}, addonDetails: {...}, UIMeasurements: [...], // Android only slowSQL: {...}, slowSQLstartup: {...}, } ```
-
-
firefox-source-docs.mozilla.org firefox-source-docs.mozilla.org
-
``` { type: <string>, // "main", "activation", "optout", "saved-session", ... id: <UUID>, // a UUID that identifies this ping creationDate: <ISO date>, // the date the ping was generated version: <number>, // the version of the ping format, currently 4
application: { architecture: <string>, // build architecture, e.g. x86 buildId: <string>, // "20141126041045" name: <string>, // "Firefox" version: <string>, // "35.0" displayVersion: <string>, // "35.0b3" vendor: <string>, // "Mozilla" platformVersion: <string>, // "35.0" xpcomAbi: <string>, // e.g. "x86-msvc" channel: <string>, // "beta" },
clientId: <UUID>, // optional environment: { ... }, // optional, not all pings contain the environment payload: { ... }, // the actual payload data for this ping type } ```
-
-
firefox-source-docs.mozilla.org firefox-source-docs.mozilla.org
-
firefox-source-docs.mozilla.org firefox-source-docs.mozilla.org
-
docs.telemetry.mozilla.org docs.telemetry.mozilla.org
Tags
Annotators
URL
-
-
connect.mozilla.org connect.mozilla.org
- Sep 2023
-
brave.com brave.com
-
Google claims this new API addresses FLoC’s serious privacy issues. Unfortunately, it does anything but. The Topics API only touches the smallest, most minor privacy issues in FLoC, while leaving its core intact. At issue is Google’s insistence on sharing information about people’s interests and behaviors with advertisers, trackers, and others on the Web that are hostile to privacy.
-
-
arstechnica.com arstechnica.com
-
Chrome now directly tracks users, generates a "topic" list it shares with advertisers.
-
-
chrome.google.com chrome.google.com
-
Disable all settings related to Privacy Sandbox
Disables "adMeasurementEnabled", "fledgeEnabled", "topicsEnabled" and "privacySandboxEnabled" for your browser.
-
-
www.theregister.com www.theregister.com
-
If a site you visit queries the Topics API, it may learn of this interest from Chrome and decide to serve you an advert about bonds or retirement funds. It also means websites can fetch your online interests straight from your browser.
The Topics API is worst than 3rd-parties cookies, anyone can query a user ad profile:
```js // document.browsingTopics() returns an array of BrowsingTopic objects. const topics = await document.browsingTopics();
// Get data for an ad creative. const response = await fetch('https://ads.example/get-creative', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(topics) });
// Get the JSON from the response. const creative = await response.json();
// Display the ad. (or not) ```
-
- Aug 2023
-
www.pewresearch.org www.pewresearch.org
-
We lived in a relatively unregulated digital world until now. It was great until the public realized that a few companies wield too much power today in our lives. We will see significant changes in areas like privacy, data protection, algorithm and architecture design guidelines, and platform accountability, etc. which should reduce the pervasiveness of misinformation, hate and visceral content over the internet.
- for: quote, quote - Prateek Raj, quote - internet regulation, quote - reducing misinformation, fake news, indyweb - support
- quote
- We lived in a relatively unregulated digital world until now.
- It was great until the public realized that a few companies wield too much power today in our lives.
- We will see significant changes in areas like
- privacy,
- data protection,
- algorithm and
- architecture design guidelines, and
- platform accountability, etc.
- which should reduce the pervasiveness of
- misinformation,
- hate and visceral content
- over the internet.
- These steps will also reduce the power wielded by digital giants.
- Beyond these immediate effects, it is difficult to say if these social innovations will create a more participative and healthy society.
- These broader effects are driven by deeper underlying factors, like
- history,
- diversity,
- cohesiveness and
- social capital, and also
- political climate and
- institutions.
- In other words,
- just as digital world is shaping the physical world,
- physical world shapes our digital world as well.
- author: Prateek Raj
- assistant professor in strategy, Indian Institute of Management, Bangalore
-
-
developer.chrome.com developer.chrome.com
-
You can mark topics provided by request headers as observed by setting an Observe-Browsing-Topics: ?1 header on the response to the request. The browser will then use those topics to calculate topics of interest for a user.
-
Call the Topics API from within that iframe:
const topics = await document.browsingTopics(); -
chrome://topics-internals
-
-
github.com github.com
-
A spec to optimize ad targeting (respectful of privacy, they say... 😂🤣).
Fuck you Google with your dystopian API:
```js // document.browsingTopics() returns an array of BrowsingTopic objects. const topics = await document.browsingTopics();
// Get data for an ad creative. const response = await fetch('https://ads.example/get-creative', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(topics) });
// Get the JSON from the response. const creative = await response.json();
// Display the ad. (or not) ```
-
-
support.google.com support.google.com
-
Edit ad privacy settings
And use Chrome only in case of necessity.
Tags
Annotators
URL
-
-
developer.chrome.com developer.chrome.com
-
On-device ad auctions to serve remarketing and custom audiences, without cross-site third-party tracking.
Naming a thing with a meaning opposite to what the named thing is...
Google is insatiable when it regards to accessing users private data. Let's block that bullshit.
-
- Jul 2023
-
www.bortzmeyer.org www.bortzmeyer.org
Tags
Annotators
URL
-
-
datatracker.ietf.org datatracker.ietf.org
-
www.scientificamerican.com www.scientificamerican.com
-
Such efforts to protect data privacy go beyond the abilities of the technology involved to also encompass the design process. Some Indigenous communities have created codes of use that people must follow to get access to community data. And most tech platforms created by or with an Indigenous community follow that group’s specific data principles. Āhau, for example, adheres to the Te Mana Raraunga principles of Māori data sovereignty. These include giving Māori communities authority over their information and acknowledging the relationships they have with it; recognizing the obligations that come with managing data; ensuring information is used for the collective benefit of communities; practicing reciprocity in terms of respect and consent; and exercising guardianship when accessing and using data. Meanwhile Our Data Indigenous is committed to the First Nations principles of ownership, control, access and possession (OCAP). “First Nations communities are setting their own agenda in terms of what kinds of information they want to collect,” especially around health and well-being, economic development, and cultural and language revitalization, among others, Lorenz says. “Even when giving surveys, they’re practicing and honoring local protocols of community interaction.”
Colonized groups such as these indigenous people have urgency to avoid colonization of their data and are doing something about it
-
- Apr 2023
-
9to5mac.com 9to5mac.com
-
Seeing how powerful AI can be for cracking passwords is a good reminder to not only make sure you‘re using strong passwords but also check:↳ You‘re using 2FA/MFA (non-SMS-based whenever possible) You‘re not re-using passwords across accounts Use auto-generated passwords when possible Update passwords regularly, especially for sensitive accounts Refrain from using public WiFi, especially for banking and similar accounts
看到人工智能在破解密码方面有多么强大,这很好地提醒了我们,不仅要确保你在使用强密码,还要检查:
-
你正在使用 2FA/MFA(尽可能不使用基于短信的)。
-
你没有在不同的账户间重复使用密码
-
尽可能使用自动生成的密码
-
定期更新密码,特别是敏感账户的密码
-
避免使用公共WiFi,尤其是银行和类似账户
-
-
Now Home Security Heroes has published a study showing how scary powerful the latest generative AI is at cracking passwords. The company used the new password cracker PassGAN (password generative adversarial network) to process a list of over 15,000,000 credentials from the Rockyou dataset and the results were wild. 51% of all common passwords were cracked in less than one minute, 65% in less than an hour, 71% in less than a day, and 81% in less than a month.
-
- Mar 2023
-
web.hypothes.is web.hypothes.is
-
at this time.
-
uses tracking pixels
-
-
infosecwriteups.com infosecwriteups.com
-
Time to dive a little deeper to see what information the barcodes actually contain. For this I will break down the previously extracted information into smaller pieces.
Information contained within boarding pass barcodes
-
-
idlewords.com idlewords.com
-
Companies that perform surveillance are attempting the same mental trick. They assert that we freely share our data in return for valuable services. But opting out of surveillance capitalism is like opting out of electricity, or cooked foods—you are free to do it in theory. In practice, it will upend your life.
Opting-out of surveillance capitalism?
Tags
Annotators
URL
-
-
www.dol.wa.gov www.dol.wa.gov
-
Does the EDL/EID card transmit my personal information? No. The RFID tag embedded in your card doesn't contain any personal identifying information, just a unique reference number.
Can this unique reference number be used to identify me (assuming they've already identified me another way and associated this number with me)? Yes!!
So this answer is a bit incomplete/misleading...
-
- Feb 2023
-
www.lawfareblog.com www.lawfareblog.com
-
It means that everything AI makes would immediately enter the public domain and be available to every other creator to use, as they wish, in perpetuity and without permission.
One issue with blanket, automatic entry of AI-generated works to the public domain is privacy: A human using AI could have good reasons not to have the outputs of their use made public.
-
-
openai.com openai.com
-
Exercising Your Rights: California residents can exercise the above privacy rights by emailing us at: support@openai.com.
Does that mean that any California resident can email to request a record of all the information OpenAI has collected about them?
-
Affiliates: We may share Personal Information with our affiliates, meaning an entity that controls, is controlled by, or is under common control with OpenAI. Our affiliates may use the Personal Information we share in a manner consistent with this Privacy Policy.
This would include Microsoft.
-
improve and/or analyze the Services
Does that mean that we are agreeing for them to use personal information in any way they choose if they deem it to help them improve their software?
-
-
web.hypothes.is web.hypothes.is
-
Your access of the website and/or use of our services, after modification, addition or deletion of the privacy policy shall be deemed to constitute acceptance by you of the modification, addition or deletion.
This sounds bad. Users can't be held to have agreed to arbitrary changes to a privacy policy, if we are not even notified about the changes.
If you make significant changes to the privacy policy you should give users 30 days' notice, and preferably get their consent again.
Here's an article about it: https://www.privacypolicies.com/blog/privacy-policy-update-notices/
-
-
storybook.js.org storybook.js.org
-
You may opt-out of the telemetry by setting Storybook's configuration element disableTelemetry to true, using the --disable-telemetry flag, or setting the environment variableSTORYBOOK_DISABLE_TELEMETRY to 1.
-
- Jan 2023
-
mek.fyi mek.fyi
-
How did it work? GNUAsk (the aspirational, mostly unreleased search engine UI) relied on hundreds of bots, running as daemons, and listening in on conversations within AOL AIM, IRC, Skype, and Yahoo public chat rooms and recording all the textual conversations.
See also: Universal Access to Knowledge raises a concern of misuse
-
-
-
1What is privacy worth?
This is a post.
-
- Dec 2022
-
www.forbes.com www.forbes.com
-
“Berla devices position CBP and ICE to perform sweeping searches of passengers’ lives, with easy access to cars' location history and most visited places and to passengers’ family and social contacts, their call logs, and even their social media feeds,” she said.
-
Cybersecurity researcher Curry told Forbes that, after seeing what could be done with just a VIN, it was “terrifying” that those identifying numbers were public.
-
-
eddesignlab.org eddesignlab.org
-
Economists explain that markets work bestwith “perfect information.” And visibilityfeeds this market by translating and sharingskills. But the price of transparency in themodern age is invaded privacy, as well as biasinherent in automated products and services
-
-
blog.cloudflare.com blog.cloudflare.com
Tags
Annotators
URL
-
-
www.washingtonpost.com www.washingtonpost.com
-
The presence of Twitter’s code — known as the Twitter advertising pixel — has grown more troublesome since Elon Musk purchased the platform.AdvertisementThat’s because under the terms of Musk’s purchase, large foreign investors were granted special privileges. Anyone who invested $250 million or more is entitled to receive information beyond what lower-level investors can receive. Among the higher-end investors include a Saudi prince’s holding company and a Qatari fund.
Twitter investors may get access to user data
I'm surprised but not surprised that Musk's dealings to get investors in his effort to take Twitter private may include sharing of personal data about users. This article makes it sound almost normal that this kind of information-sharing happens with investors (inclusion of the phrase "information beyond what lower-level investors can receive").
-
-
themarkup.org themarkup.org
-
Meta's receipt of tax information via tracking pixels on tax preparer websites is the subject of a federal lawsuit. The tax preparing sites are not participants in the lawsuit (yet?).
-
- Nov 2022
-
medium.com medium.com
-
hat we want is to be able to leave Facebook and still talk to our friends, instead of having many Facebooks.
What about Matrix?
-
-
ariadne.space ariadne.space
-
From a technical point of view, the IndieWeb people have worked on a number of simple, easy to implement protocols, which provide the ability for web services to interact openly with each other, but in a way that allows for a website owner to define policy over what content they will accept.
Thought you might like Web Monetization.
-
-
en.wikipedia.org en.wikipedia.org
-
Donations
To add some other intermediary services:
- ko-fi (site for contribution)
- GitHub sponsors (for GitPages)
- itch.io (for games)
- Gumroad (for sites and repositories)
- Patreon (for fan interaction)
To add a service for groups:
To add a service that enables fans to support the creators directly and anonymously via microdonations or small donations by pre-charging their Coil account to spend on content streaming or tipping the creators' wallets via a layer containing JS script following the Interledger Protocol proposed to W3C:
If you want to know more, head to Web Monetization or Community or Explainer
Disclaimer: I am a recipient of a grant from the Interledger Foundation, so there would be a Conflict of Interest if I edited directly. Plus, sharing on Hypothesis allows other users to chime in.
Tags
- web standards
- sponsors
- mozilla
- nonprofit
- pay-what-you-want
- web
- payment
- exclusive
- mozilla festival
- plug-in
- hugo
- tips
- uphold
- wallet
- vuepress
- gridsome
- tessy
- open web
- jekyll
- stream
- gaming
- fans
- svelte
- extension
- gatehub
- gratuity
- pricing strategies
- open source
- games
- open
- video
- contribution
- mozfest
- wordpress
- coil
- art
- Interledger Protocol
- FOSS
- Patreon
- payment pointer
- open-source
- freemium
- microdonation
- gumroad
- pricing
- protocol
- donation
- monetization
- youtube
- open collective
- model
- ngx
- gatsby
- moodle
- web monetization
- pay what you want
- subscriptions
- github
- education
- Consortium
- 11ty
- WWW
- film
- pipe web
- revenue sharing
- micro-donation
- w3c
- podcast
- dev.to
- browser
- strategies
- gftw
- collective
- API
- Interledger
- online ledger
- revenue
- micropayment
- research
- pwyw
- ko-fi
- tools
- premium
- privacy
- community
- business
Annotators
URL
-
-
www.theatlantic.com www.theatlantic.com
-
Hidden below all of this is the normalization of surveillance that consistently targets marginalized communities. The difference between a smartwatch and an ankle monitor is, in many ways, a matter of context: Who wears one for purported betterment, and who wears one because they are having state power enacted against them?
-
The conveniences promised by Amazon’s suite of products may seem divorced from this context; I am here to tell you that they’re not. These “smart” devices all fall under the umbrella of what the digital-studies scholar David Golumbia and I call “luxury surveillance”—that is, surveillance that people pay for and whose tracking, monitoring, and quantification features are understood by the user as benefits.
-
-
themarkup.org themarkup.org
-
Some of the sensitive data collection analyzed by The Markup appears linked to default behaviors of the Meta Pixel, while some appears to arise from customizations made by the tax filing services, someone acting on their behalf, or other software installed on the site. Report Deeply and Fix Things Because it turns out moving fast and breaking things broke some super important things. Give Now For example, Meta Pixel collected health savings account and college expense information from H&R Block’s site because the information appeared in webpage titles and the standard configuration of the Meta Pixel automatically collects the title of a page the user is viewing, along with the web address of the page and other data. It was able to collect income information from Ramsey Solutions because the information appeared in a summary that expanded when clicked. The summary was detected by the pixel as a button, and in its default configuration the pixel collects text from inside a clicked button. The pixels embedded by TaxSlayer and TaxAct used a feature called “automatic advanced matching.” That feature scans forms looking for fields it thinks contain personally identifiable information like a phone number, first name, last name, or email address, then sends detected information to Meta. On TaxSlayer’s site this feature collected phone numbers and the names of filers and their dependents. On TaxAct it collected the names of dependents.
Meta Pixel default behavior is to parse and send sensitive data
Wait, wait, wait... the software has a feature that scans for privately identifiable information and sends that detected info to Meta? And in other cases, the users of the Meta Pixel decided to send private information ot Meta?
-
-
morningconsult.com morningconsult.com
-
Although complicated, Gen Z’s relationship with data privacy should be a consideration for brands when strategizing their data privacy policies and messaging for the future. Expectations around data privacy are shifting from something that sets companies apart in consumers’ minds to something that people expect the same way one might expect a service or product to work as advertised. For Gen Zers, this takes the form of skepticism that companies will keep their data safe, and their reluctance to give companies credit for getting it right means that good data privacy practices will increasingly be more about maintaining trust than building it.
Gen-Z expectations are complicated
The Gen-Z generation have notably different expectations about data privacy than previous generations. "Libraries" wasn't among the industry that showed up in their survey results. That Gen-Z expects privacy built in makes that factor a less differentiating characteristic as compared to older generations. It might also be harder to get trust back from members of the Gen-Z population if libraries surprise those users with data handling practices that they didn't expect.
-
-
-
tech.asu.edu tech.asu.edu
-
“You have to assume that things can go wrong,” shared Waymo’s head of cybersecurity, Stacy Janes. “You can’t just design for this success case – you have to design for the worst case.”
Future proofing by asking "what if we're wrong?"
-
- Oct 2022
-
www.bankinfosecurity.com www.bankinfosecurity.com
-
A Midwestern hospital system is treating its use of Google and Facebook web tracking technologies as a data breach, notifying 3 million individuals that the computing giants may have obtained patient information.
Substitute “library” for “hospital”
In an alternate universe: “A Midwestern library system is treating its use of Google and Facebook web tracking technologies as a data breach, notifying 3 million individuals that the computing giants may have obtained search and borrowing histories.”
-
-
simplephone.tech simplephone.tech
-
On the other end, there was The Good Phone Foundation, a not-for-profit organization founded with a mission to create an open, transparent, and secure mobile ecosystem outside of Big Tech’s reach, who just released their own Android-based mobile OS and were looking for apps to rely on. They contacted me, and after a couple of calls, we realized that partnering up on the smartphone makes a lot of sense for both of us. So, here we are, introducing you to our brand new Simple Phone. Only having control over both software and hardware ensures the ultimate privacy and security. The target audience consists of more privacy-oriented people that do not want to be tracked or rely on big corporations, Google Play, etc. It focuses on people who just want to get things done in a simple way without having to keep closing ads and wondering what does the system do in the background. Not to mention consistency again as the core apps are developed by us. Hope you will like it just like we do 🙂
Simple Phone's effort to release its own mobile OS is promising for ordinary users. Because Simple Mobile Tools represents a full suite of basic Android applications, in can, ideally, provide a privacy-friendly and user-friendly alternative to stock Android by providing a unified suite of apps. /e/ OS (aka Murena) is attempting something similar, but its app collection is not quite as unified as the Simple Mobile suite.
Tags
Annotators
URL
-
-
ashfurrow.com ashfurrow.com
-
https://ashfurrow.com/blog/mastodon-technology-shutdown/
Mastodon.technology is shutting down by 2022-12-01 due to personal and admin tax related reasons. Sounds like it's being done in an ethical and reasonably kind way.
-
-
www.dentons.com www.dentons.com
-
Inspirée du Règlement général sur la protection des données (RGPD) de l’Union européenne, la nouvelle loi québécoise place la barre plus haut en introduisant de nouvelles normes pour les droits individuels à la vie privée
-
-
-
in many ways, Law 25 is the most stringent of the three regimes
-
Impact assessments: Law 25 is broad and requires a PIR to be carried out whenever conditions are met, regardless of the level of risk. The GDPR is less stringent, only requiring assessments in cases where processing is likely to result in a ‘high risk’ to rights and freedoms. Because the CCPA does not specifically focus on accountability-related obligations, it does not mandate impact assessments.
-
Privacy by default: Bill 64’s “confidentiality by default” clause is far broader in scope and significantly more stringent than the “privacy by design” concept under the GDPR. The CCPA does not provide for this concept at all, instead taking an “after-the-event” remedial approach.
-
-
blog.didomi.io blog.didomi.io
-
exige qu'une AIPD soit réalisée à chaque fois que la situation le nécessite et quel que soit le niveau de risque
-
La confidentialité par défaut : La clause de "confidentialité par défaut" du projet de loi 64 a une portée beaucoup plus vaste et est beaucoup plus stricte que le concept de "confidentialité par conception" prévu par le RGPD. Le CCPA adopte plutôt une approche corrective "après coup".
-
-
cdn-contenu.quebec.ca cdn-contenu.quebec.ca
-
En cas de non-respect de la Loi, la Commission d’accès à l’information pourra imposer des sanctionsimportantes, qui pourraient s’élever jusqu’à 25 M$ ou à 4 % du chiffre d’affaires mondial. Cette sanctionsera proportionnelle, notamment, à la gravité du manquement et à la capacité de payer de l’entreprise.ENTREPRISES
-
- Sep 2022
-
-
Denmark’s data protection regulator found that local schools did not really understand what Google was doing with students’ data and as a result blocked around 8,000 students from using the Chromebooks that had become a central part of their daily education.
Danish data regulator puts a temporary ban on Google education products
-
-
kevquirk.com kevquirk.com
-
If someone came up to you in the street, said they’re from an online service provider and requested you store all of the above data about you with them, I imagine for many the answer would be a resounding NO!
See: Surveillance Camera Man * https://boingboing.net/2012/11/02/surveillance-camera-man-wants.html * https://www.youtube.com/watch?v=X9sVqKFkjiY
-
- Aug 2022
-
www.theverge.com www.theverge.com
-
University can’t scan students’ rooms during remote tests, judge rules
Room scan by proctoring tools violates protection against unreasonable searches Ohio court rules (US const 4th amendment) Univ defense was 'it's standard industry practice' and 'others did not complain'. In other words no actual moral consideration was made by univ. This is so bad, even without the fact that a third party keeps the recording of the video scan of this student's bedroom.
Where there's a need for remote test taking, why try to copy over the cheating controls from in-person test taking? How about adapting the test content on the assumption that students will have material available to them during the test, reducing the proctoring need to only assuring the actual student is taking the test.
-
-
lp.beekeeper.io lp.beekeeper.io
-
Your personal data will be shared both within Beekeeper associated offices globally and with Greenhouse Software, Inc., a cloud services provider located in the United States of America and engaged by Controller to help manage its recruitment and hiring process on Controller’s behalf.
Personal data will be accessible to different branches (i.e., national affiliates) of Beekeeper.
Tags
Annotators
URL
-
-
www.netgear.com www.netgear.com
-
NETGEAR is committed to providing you with a great product and choices regarding our data processing practices. You can opt out of the use of the data described above by contacting us at analyticspolicy@netgear.com
You may opt out of these data use situations by emailing analyticspolicy@netgear.com.
-
Marketing. For example, information about your device type and usage data may allow us to understand other products or services that may be of interest to you.
All of the information above that has been consented to, can be used by NetGear to make money off consenting individuals and their families.
-
USB device
This gives Netgear permission to know what you plug into your computer, be it a FitBit, a printer, scanner, microphone, headphones, webcam — anything not attached to your computer.
-
- Jul 2022
-
www.nbcnews.com www.nbcnews.com
-
In the wake of Roe v. Wade being overturned, online privacy is on everyone's minds. But according to privacy experts, the entire way we think about and understand what 'privacy' actually means... is wrong. In this new Think Again, NBC News Correspondent Andrew Stern dives deep into digital privacy — what it really means, how we got to this point, how it impacts every facet of our lives, and how little of it we actually have.
In the wake of Roe v. Wade being overturned, online privacy is on everyone's minds. But according to privacy experts, the entire way we think about and understand what 'privacy' actually means... is wrong. In this new Think Again, NBC News Correspondent Andrew Stern dives deep into digital privacy — what it really means, how we got to this point, how it impacts every facet of our lives, and how little of it we actually have.
-
-
www.mojeek.com www.mojeek.comMojeek1
-
Mojeek
Mojeek is the 4th largest English lang. web search engine after Google, Bing and Yandex which has it's own index, crawler and algo. Index has passed 5.7 billion pages. Growing. Privacy based.
It uses it's own index with no backfill from others.
Tags
Annotators
URL
-
-
www.theverge.com www.theverge.com
-
she’s being dragged into the public eye nonetheless.
Wow... I have heard of instances similar to this one. A stranger narrates the life of another stranger online, it goes viral and the identities of everyone are revealed. To me it seemed meaningless I never thought that the people involved could just want their privacy. I find it very scary how this can happen to anyone. Another reason why I limit my social media usage. I found myself to be engaging with very negative commentary and it really affected my mental health. I wonder how this womans mental health is going. Pretty much the whole world knows about her know unfortunately.
-
-
www.theatlantic.com www.theatlantic.com
-
Something has shifted online: We’ve arrived at a new era of anonymity, in which it feels natural to be inscrutable and confusing—forget the burden of crafting a coherent, persistent personal brand. There just isn’t any good reason to use your real name anymore. “In the mid 2010s, ambiguity died online—not of natural causes, it was hunted and killed,” the writer and podcast host Biz Sherbert observed recently. Now young people are trying to bring it back. I find this sort of exciting, but also unnerving. What are they going to do with their newfound freedom?
-
- Jun 2022
-
-
Companies need to actually have an ethics panel, and discuss what the issues are and what the needs of the public really are. Any ethics board must include a diverse mix of people and experiences. Where possible, companies should look to publish the results of these ethics boards to help encourage public debate and to shape future policy on data use.
-
-
www.nytimes.com www.nytimes.com
-
The goal is to gain “digital sovereignty.”
the age of borderless data is ending. What we're seeing is a move to digital sovereignty
-
-
grapheneos.org grapheneos.org
-
Using the network-provided DNS servers is the best way to blend in with other users. Network and web sites can fingerprint and track users based on a non-default DNS configuration.
-
-
ucsdnews.ucsd.edu ucsdnews.ucsd.edu
-
All wireless devices have small manufacturing imperfections in the hardware that are unique to each device. These fingerprints are an accidental byproduct of the manufacturing process. These imperfections in Bluetooth hardware result in unique distortions, which can be used as a fingerprint to track a specific device. For Bluetooth, this would allow an attacker to circumvent anti-tracking techniques such as constantly changing the address a mobile device uses to connect to Internet networks.
Tracking that evades address changes
An operating system can change the hardware address it broadcasts in avoid tracking. But subtle differences in the signal itself can still be identified and tracked.
-
-
-
Free public projects private projects starting at $9/month per project
For many tools and apps payment for privacy is becoming the norm.
Examples: - Kumu.io - Github for private repos - ...
pros: - helps to encourage putting things into the commons
cons: - Normalizes the idea of payment for privacy which can be a toxic tool.
discuss...
-
-
www.eff.org www.eff.org
-
the one thing that you have to keep conveying to people about the consequences of surveillance is that it's all very well to say that you have nothing to hide, but when you're spied upon, everybody that's connected to you gets spied upon. And if we don't push back, the most vulnerable people in society, the people that actually keep really massive violations of human rights and illegality in check, they're the people who get most affected.
"I Have Nothing To Hide" counter-argument
Even if you have nothing to hide, that doesn't mean that those you are connected with aren't also being surveilled and are part of targeted communities.
-
- May 2022
-
phirephoenix.com phirephoenix.com
-
For example, we know one of the ways to make people care about negative externalities is to make them pay for it; that’s why carbon pricing is one of the most efficient ways of reducing emissions. There’s no reason why we couldn’t enact a data tax of some kind. We can also take a cautionary tale from pricing externalities, because you have to have the will to enforce it. Western Canada is littered with tens of thousands of orphan wells that oil production companies said they would clean up and haven’t, and now the Canadian government is chipping in billions of dollars to do it for them. This means we must build in enforcement mechanisms at the same time that we’re designing principles for data governance, otherwise it’s little more than ethics-washing.
Building in pre-payments or a tax on data leaks to prevent companies neglecting negative externalities could be an important stick in government regulation.
While it should apply across the board, it should be particularly onerous for for-profit companies.
-
Even with data that’s less fraught than our genome, our decisions about what we expose to the world have externalities for the people around us.
We need to think more about the externalities of our data decisions.
-
- Apr 2022
-
www.playbuzz.com www.playbuzz.com
-
This Playbuzz Privacy Policy (“Policy”) outlines what personal information is collected by Playbuzz Ltd. (“Playbuzz”, “we”, “us” or “our”), how we use such personal information, the choices you have with respect to such personal information, and other important information.
We keep your personal information personal and private. We will not sell, rent, share, or otherwise disclose your personal information to anyone except as necessary to provide our services or as otherwise described in this Policy.
Tags
Annotators
URL
-
-
minds.wisconsin.edu minds.wisconsin.edu
-
Dorothea Salo (2021) Physical-Equivalent Privacy, The Serials Librarian, DOI: 10.1080/0361526X.2021.1875962
Permanent Link: http://digital.library.wisc.edu/1793/81297
Abstract
This article introduces and applies the concept of “physical-equivalent privacy” to evaluate the appropriateness of data collection about library patrons’ use of library-provided e‑resources. It posits that as a matter of service equity, any data collection practice that causes e‑resource users to enjoy less information privacy than users of an information-equivalent print resource is to be avoided. Analysis is grounded in real-world e‑resource-related phenomena: secure (HTTPS) library websites and catalogs, the Adobe Digital Editions data-leak incident of 2014, and use of web trackers on e‑resource websites. Implications of physical-equivalent privacy for the SeamlessAccess single-sign-on proposal will be discussed.
-
-
99percentinvisible.org 99percentinvisible.org
-
a child had gone missing in our town and the FBI came to town to investigate immediately and had gone to the library. They had a tip and wanted to seize and search the library’s public computers. And the librarians told the FBI that they needed to get a warrant. The town was grief stricken and was enraged that the library would, at a time like that, demand that the FBI get a warrant. Like everyone in town was like, are you kidding me? A child is missing and you’re– and what? This town meeting afterwards, the library budget, of course, is up for discussion as it is every year, and the people were still really angry with the library, but a patron and I think trustee of the library – again, a volunteer, someone living in town – an elderly woman stood up and gave the most passionate defense of the Fourth Amendment and civil liberties to the people on the floor that I have ever witnessed.
An example of how a library in Vermont stood up to a warrantless request from the FBI to seize and search public library computers. This could have impacted the library's budget when the issue was brought to a town meeting, but a library patron was a passionate advocate for the 4th amendment.
-
-
twitter.com twitter.com
-
Adam Kucharski. (2021, March 24). This is an interesting perspective on Taiwan (& glad it mentions data/privacy), although I’d like to see more references to what local officials were actually saying about approach in real-time, rather than what UK-based researchers later say it was: Https://t.co/FDu0mQoISh 1/ [Tweet]. @AdamJKucharski. https://twitter.com/AdamJKucharski/status/1374638777814167555
-
-
towardsdatascience.com towardsdatascience.com
-
K-Anonymity, L-Diversity, and T-ClosenessIn this section, I will introduce three techniques that can be used to reduce the probability that certain attacks can be performed. The simplest of these methods is k-anonymity, followed by l-diversity, and then followed by t-closeness. Other methods have been proposed to form a sort of alphabet soup, but these are the three most commonly utilized. With each of these, the analysis that must be performed on the dataset becomes increasingly complex and undeniably has implications on the statistical validity of the dataset.
privacy metrics
-
-
nakamotoinstitute.org nakamotoinstitute.org
-
Privacy is not secrecy. A private matter is something one doesn't want the whole world to know, but a secret matter is something one doesn't want anybody to know.
Privacy is the power to decide when and what is secret and who to.
Tags
Annotators
URL
-
-
onezero.medium.com onezero.medium.com
-
I thought that the point of disappearing messages was to eat your cake and have it too, by allowing you to send a message to your adversary and then somehow deprive them of its contents. This is obviously a stupid idea.But the threat that Snapchat — and its disappearing message successors —was really addressing wasn’t communication between untrusted parties, it was automating data-retention agreements between trusted parties.
Why use a disappearing message service
The point of a disappearing message service is to have the parties to the message agree on the data-retention provisions of a message. The service automates that agreement by deleting the message at the specified time. The point isn't to send a message to an adversary and then delete it so they can't prove that it has been sent. There are too many ways of capturing the contents of a message—as simple as taking a picture of the message with another device.
-
-
www.vox.com www.vox.com
-
Weinberg’s tweet announcing the change generated thousands of comments, many of them from conservative-leaning users who were furious that the company they turned to in order to get away from perceived Big Tech censorship was now the one doing the censoring. It didn’t help that the content DuckDuckGo was demoting and calling disinformation was Russian state media, whose side some in the right-wing contingent of DuckDuckGo’s users were firmly on.
There is an odd sort of self-selected information bubble here. DuckDuckGo promoted itself as privacy-aware, not unfiltered. On their Sources page, they talk about where they get content and how they don't sacrifice privacy to gather search results. Demoting disinformation sources in their algorithms would seem to be a good thing. Except if what you expect to see is disinformation, and then suddenly the search results don't match your expectations.
-
- Mar 2022
-
static1.squarespace.com static1.squarespace.com
-
Thus,information about people and their behaviour is made visible to other people, systems andcompanies.
"Data trails"—active information and passive telemetry—provide a web of details about a person's daily life, and the analysis of that data is a form of knowledge about a person.
-
- Feb 2022
-
blog.codeberg.org blog.codeberg.org
-
Others because they want privacy
AIUI, your account's contribution graph and feed are still public, not private, without a way to opt out—just like on GitHub.
-
-
addons.mozilla.org addons.mozilla.org
- Dec 2021
-
library.educause.edu library.educause.edu
-
Efforts to clarify and disseminatethe differences between “privacy as advocacy” (e.g.,privacy is a fundamental right; privacy is an ethicalnorm) and “privacy as compliance” (e.g., ensuringprivacy policies and laws are followed; privacyprograms train, monitor, and measure adherence torules) help frame conversations and set expectations.
This is an interesting distinction... privacy-because-it-is-the-right-thing-to-do versus privacy-because-you-must. I think the latter is where most institutions are today. It will take a lot more education to get institutions to the former.
-
As informed and engagedstakeholders, students understand how and why theirinstitutions use academic and personal data.
Interesting that there is a focus here on advocacy from an active student body. Is it the expectation that change from some of the more stubborn areas of the campus would be driven by informed student push-back? This section on "Students, Faculty, and Staff" doesn't have the same advocacy role from the other portions of the campus community.
-
-
www.marugroup.net www.marugroup.net
-
Questions, comments and requests, including any complaints, regarding us or this privacy policy are welcomed and should be addressed to privacy@marugroup.net.
However, if you do this then your email, IP, broswer etc will be collected and shared as per the information above. To be safer, I would write a letter, stick a stamp on the envelope and send it in.
-
stored at, a destination outside the European Economic Area ("EEA").
Why? is that allowed? I don't think that I would be happy about that as I am not reassured that 'taking reasonable steps' is actually appropriate considering one of those would be to host within regions specified by GDPR
-
third party, in which case personal data held by it about its customers will be one of the transferred assets.
I was going to respond to the survey until I saw this. I am offering to provide feedback for free and yet my personal information is collected and becomes part of the sale of the business in the form of an asset. The question is why is my personal information being held for any length of time after I have completed the survey? Isn't that a violation of GDPR?
-
In the event that we sell or buy any business or assets, in which case we will disclose your personal data to the prospective seller or buyer of such business or assets.
Why? I came across this privacy policy as I had been asked to respond to a survey about the website. Not only am I giving my feedback for free but then they want to take my personal information and give it away to unknown buyers and sellers (third parties) all of whom are fictitious and in the future?
Tags
Annotators
URL
-
-
www.washingtonpost.com www.washingtonpost.com
-
About 7 in 10 Americans think their phone or other devices are listening in on them in ways they did not agree to.
I'm enough of a tinfoil hat wearer to this this might be true. Especially since my google home talks to me entirely too much when I'm not talking to it.
-
- Nov 2021
-
nayafia.substack.com nayafia.substack.com
-
There Is No Antimimetics Division (qntm): This is the best new sci fi I've read in recent memory, I think because it feels fresh and modern, tackling some of the hardest social questions that the world is facing today. It's about antimemes, defined as "an idea with self-censoring properties...which, by its intrinsic nature, discourages or prevents people from spreading it."
I like the idea of antimemes. The tougher question is how to actually implement it on the web?
Is this just the idea of a digital secret?
"The only way for two computers to keep a secret on the web is if all the computers are dead."—Chris Aldrich
-
-
eur-lex.europa.eu eur-lex.europa.eu
-
Facebook Ireland
Tags
Annotators
URL
-
-
www.schneier.com www.schneier.com
-
Pretty much anything that can be remembered can be cracked. There’s still one scheme that works. Back in 2008, I described the “Schneier scheme”: So if you want your password to be hard to guess, you should choose something that this process will miss. My advice is to take a sentence and turn it into a password. Something like “This little piggy went to market” might become “tlpWENT2m”. That nine-character password won’t be in anyone’s dictionary. Of course, don’t use this one, because I’ve written about it. Choose your own sentence — something personal.
Good advice on creating secure passwords.
-
-
osf.io osf.io
-
Chen, W., & Zou, Y. (2021). Why Zoom Is Not Doomed Yet: Privacy and Security Crisis Response in the COVID-19 Pandemic. SocArXiv. https://doi.org/10.31235/osf.io/mf935
-
-
www.forbes.com www.forbes.com
-
What consumers are now storing in cloud services encompasses the whole of their digital lives.
-
-
safety.google safety.google
-
-
ISO 29100/Privacy Framework [2] defines the privacy principles as:1.Consent and choice,2.Purpose legitimacy and specification,3.Collection limitation,4.Data minimization,5.Use, retention and disclosure limitation,6.Accuracy and quality,7.Openness, transparency and notice,8.Individual participation and access,9.Accountability,10.Information security, and11.Privacy compliance.
-
- Oct 2021
-
www.vice.com www.vice.com
-
A screenshot from the document providing an overview of different data retention periods. Image: Motherboard.
Is it possible that FBI stores this data on us?
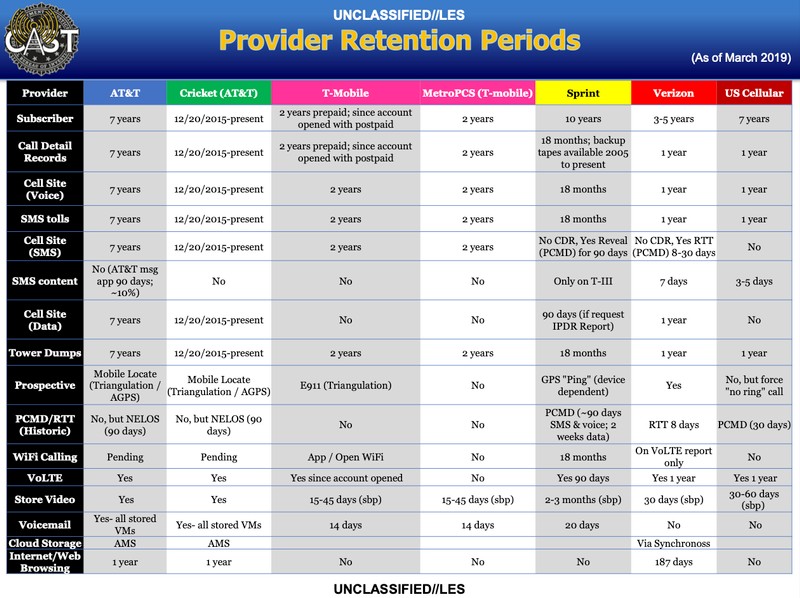
-
-
-
We will also show you how to de-link your Chrome profile from your Google account(s) by stopping Chrome from syncing with Google in the first place. This will help keep your Chrome profile separate from your Google account and enhance your online privacy.
-
To do that, Chrome automatically links your Chrome profile to a Google account when you sign in to any Google service on the web. That helps Google deliver a ‘seamless experience’ across all devices by letting you sync your history, bookmarks, passwords, etc., across multiple devices. Meanwhile, privacy-conscious users see this as a major threat to their online privacy and advise users to remove their Google account from Chrome.
-
As mentioned already, Chrome automatically signs you in to your Google account every time you sign into a Google service, like Gmail, YouTube, Google Photos, etc. It also links your current Chrome profile to that account. While Google says that it does so to offer a ‘seamless experience’, it is a privacy nightmare for many users.
-
- Sep 2021
-
www.nature.com www.nature.com
-
Zuckerman, E. (2021). Demand five precepts to aid social-media watchdogs. Nature, 597(7874), 9–9. https://doi.org/10.1038/d41586-021-02341-9
-
- Aug 2021
-
protonmail.com protonmail.com
-
You can request that Zoom delete any and all information they hold on you. Information on your data rights and how to get in contact with Zoom to request they erase your data can be found in their privacy policy. Once you have made the request, follow up to ensure you get confirmation that your data has been removed from their servers.
Tags
Annotators
URL
-
-
-
U.S. Senate Subcommittee on Communications, Technology, Innovation, and the Internet, "Optimizing for Engagement: Understanding the Use of Persuasive Technology on Internet Platforms," 25 June 2019, www.commerce.senate.gov/2019/6/optimizing-for-engagement-understanding-the-use-of-persuasive-technology-on-internet-platforms.
Perhaps we need plurality in the areas for which social data are aggregated?
What if we didn't optimize for engagement, but optimized for privacy, security, or other axes in the space?
-
- Jul 2021
-
time.com time.com
-
How anti-vaccination websites build audiences and monetize misinformation %. (2021, March 10). First Draft. https://firstdraftnews.org:443/articles/antivaccination-audiences-monetize/
-
-
-
stackoverflow.com stackoverflow.com
-
whereas now, they know that user@domain.com was subscribed to xyz.net at some point and is unsubscribing. Information is gold. Replace user@domain with abcd@senate and xyz.net with warezxxx.net and you've got tabloid gold.
-
-
www.dailybreeze.com www.dailybreeze.com
-
Roberts noted that the risks of physical danger to donors are heightened “with each passing year” as changes in technology enables “anyone with access to a computer” to “compile a wealth of information about” anyone.
He's going to be shocked at what's in his Facebook (shadow) profile...
-