Flow Cytometry Analysis with R: the flowCore package
slides.pdf are informative
Flow Cytometry Analysis with R: the flowCore package
slides.pdf are informative
‘A bit of a mystery’: Why hospital admissions for Covid in England are going down | Coronavirus | The Guardian. (n.d.). Retrieved 8 October 2021, from https://www.theguardian.com/world/2021/sep/24/a-bit-of-a-mistery-why-england-covid-cases-are-going-down-despite-ease-of-restrictions
<small><cite class='h-cite via'>ᔥ <span class='p-author h-card'>Cory Doctorow </span> in Pluralistic: 29 Sep 2021 – Pluralistic: Daily links from Cory Doctorow (<time class='dt-published'>09/30/2021 10:07:35</time>)</cite></small>
This fundamental truth (expressed in economic notation as r > g, or "return on capital is greater than economic growth") means that "meritocracy" is a lie: the richest people in a market economy aren't the people who do the best work, it's the people who started off rich.
Thomas Piketty's r > g shows that meritocracy is a lie in that the richest people aren't the ones that do the best or most productive work, but simply those who start of rich.
https://www.youtube.com/watch?v=rhgwIhB58PA
Learning styles have been debunked.
Learning styles: V.A.R.K. model originated by Neil Flemiing stands for:
Pashler, H., McDaniel, M., Rohrer, D., & Bjork, R. (2008). Learning styles: Concepts and evidence. Psychological science in the public interest, 9(3), 105-119. — https://ve42.co/Pashler2008
Willingham, D. T., Hughes, E. M., & Dobolyi, D. G. (2015). The scientific status of learning styles theories. Teaching of Psychology, 42(3), 266-271. — https://ve42.co/Willingham
Massa, L. J., & Mayer, R. E. (2006). Testing the ATI hypothesis: Should multimedia instruction accommodate verbalizer-visualizer cognitive style?. Learning and Individual Differences, 16(4), 321-335. — https://ve42.co/Massa2006
Riener, C., & Willingham, D. (2010). The myth of learning styles. Change: The magazine of higher learning, 42(5), 32-35.— https://ve42.co/Riener2010
Husmann, P. R., & O'Loughlin, V. D. (2019). Another nail in the coffin for learning styles? Disparities among undergraduate anatomy students’ study strategies, class performance, and reported VARK learning styles. Anatomical sciences education, 12(1), 6-19. — https://ve42.co/Husmann2019
Snider, V. E., & Roehl, R. (2007). Teachers’ beliefs about pedagogy and related issues. Psychology in the Schools, 44, 873–886. doi:10.1002/pits.20272 — https://ve42.co/Snider2007
Fleming, N., & Baume, D. (2006). Learning Styles Again: VARKing up the right tree!. Educational developments, 7(4), 4. — https://ve42.co/Fleming2006
Rogowsky, B. A., Calhoun, B. M., & Tallal, P. (2015). Matching learning style to instructional method: Effects on comprehension. Journal of educational psychology, 107(1), 64. — https://ve42.co/Rogowskyetal
Coffield, Frank; Moseley, David; Hall, Elaine; Ecclestone, Kathryn (2004). — https://ve42.co/Coffield2004
Furey, W. (2020). THE STUBBORN MYTH OF LEARNING STYLES. Education Next, 20(3), 8-13. — https://ve42.co/Furey2020
Dunn, R., Beaudry, J. S., & Klavas, A. (2002). Survey of research on learning styles. California Journal of Science Education II (2). — https://ve42.co/Dunn2002
108,574
R&D expenses account for 13% of Total Revenue
We think R is a great place to start your data science journey because it is an environment designed from the ground up to support data science. R is not just a programming language, but it is also an interactive environment for doing data science. To support interaction, R is a much more flexible language than many of its peers. This flexibility comes with its downsides, but the big upside is how easy it is to evolve tailored grammars for specific parts of the data science process. These mini languages help you think about problems as a data scientist, while supporting fluent interaction between your brain and the computer.
Why do 87% of data science projects never make it into production?
It turns out that this phrase doesn't lead to an existing research. If one goes down the rabbit hole, it all ends up with dead links
If Covid-19 is a seasonal virus, why is it spreading during the summer? | Francois Balloux | The Guardian. (n.d.). Retrieved July 19, 2021, from https://www.theguardian.com/commentisfree/2021/jul/16/covid-19-seasonal-virus-spreading-during-summer-pandemic
New study estimates mask wearing could cut R number by 25%, not 0.25—Full Fact. (n.d.). Retrieved July 15, 2021, from https://fullfact.org/online/andy-burnham-mayor-manchester-masks-misquote/
David Fisman. (2021, July 8). Fascinating new preprint on delta vs older variants in well-investigated outbreaks in China. Viral load for delta is 3 log higher, and latent period is shorter too (estimate is 4 days vs 6 days). This may explain much higher R estimates which may be due to elevated viral load [Tweet]. @DFisman. https://twitter.com/DFisman/status/1413126886570536963
ReconfigBehSci. (2021, June 14). RT @AdamJKucharski: Compare relationship between R and proportion of sequences consistent with the B.1.1.7 variant in autumn 2020 (below le… [Tweet]. @SciBeh. https://twitter.com/SciBeh/status/1404604886117797888
Anthony Costello on Twitter. (n.d.). Twitter. Retrieved 1 March 2021, from https://twitter.com/globalhlthtwit/status/1323747414923202562
‘Expert Reaction to Non-Peer Reviewed Modelling Presented on a Dashboard Suggesting That “a Herd Immunity Threshold (of 73.4%) Will Be Reached This Week on 9 April 2021” | Science Media Centre’. Accessed 12 April 2021. https://www.sciencemediacentre.org/expert-reaction-to-non-peer-reviewed-modelling-presented-on-a-dashboard-suggesting-that-a-herd-immunity-threshold-of-73-4-will-be-reached-this-week-on-9-april-2021/.
The impact of reopening schools on SARS-CoV-2 transmission in England. (n.d.). LSHTM. Retrieved 10 March 2021, from https://www.lshtm.ac.uk/newsevents/news/2021/impact-reopening-schools-sars-cov-2-transmission-england
Confounding vs. Effect modification – The Stats Geek. (n.d.). Retrieved February 27, 2021, from https://thestatsgeek.com/2021/01/13/confounding-vs-effect-modification/
unnest_wider
unnest_wider( data, col, names_sep = NULL, simplify = TRUE, names_repair = "check_unique", ptype = list(), transform = list() )
unnest_wider
unnest_wider( data, col, names_sep = NULL, simplify = TRUE, names_repair = "check_unique", ptype = list(), transform = list() )
unnest_wider
unnest_wider( data, col, names_sep = NULL, simplify = TRUE, names_repair = "check_unique", ptype = list(), transform = list() )
unnest_longer
unnest_longer( data, col, values_to = NULL, indices_to = NULL, indices_include = NULL, names_repair = "check_unique", simplify = TRUE, ptype = list(), transform = list() )
unnest_longer
unnest_longer( data, col, values_to = NULL, indices_to = NULL, indices_include = NULL, names_repair = "check_unique", simplify = TRUE, ptype = list(), transform = list() )
unnest_longer
unnest_longer( data, col, values_to = NULL, indices_to = NULL, indices_include = NULL, names_repair = "check_unique", simplify = TRUE, ptype = list(), transform = list() )
unnest_wider
unnest_wider( data, col, names_sep = NULL, simplify = TRUE, names_repair = "check_unique", ptype = list(), transform = list() )
unnest_wider
unnest_wider( data, col, names_sep = NULL, simplify = TRUE, names_repair = "check_unique", ptype = list(), transform = list() )
hoist
hoist( .data, .col, ..., .remove = TRUE, .simplify = TRUE, .ptype = list(), .transform = list() )
"%>%" shortcut Ctrl + Shift + M
Red Comunicacional Insurgente, la Cadena Radial Bolivariana Voz de la Resistencia y la Comisión Nacional de Comunicaciones
Medios de comunicación #NuevaMarquetalia
data.frames (actually, tibbles
Sass
Define variables, such as colors (e.g. $primary: #337ab7) in Sass (styles.scss) then compile to css for web.
R library "bootstraplib" built on foundation of "sass".
Use "run_with_themer()" to get a live preview GUI for customizing bootstrap theme.
Also, use "shinyOptions(plot.autocolors=TRUE)" at top of app to get plot outputs that respect Dark Mode.
CURSO R
flow cytometry data were analyzed in R using the flowCore Bioconductor package (
Let’s fit regression line to our model:
plot() and lines() seem to plot regression lines
R packages are also often constantly updated on CRAN or GitHub, so you may want to update them once in a while:
You need to get out of the habit of thinking using quotes is ugly. Not using them is ugly! Why? Because you've created a function that can only be used interactively - it's very difficult to program with it. – hadley
Does it seem like Hadley still stands by this statement after tidy evaluation from this article <Do you need tidyeval>
In practice, functional programming is all about hiding for loops, which are abstracted away by the mapper functions that automate the iteration.
All figures were created using R Statistical Computing Software version 3.6.3 (R Core Team, 2020), relying primarily on the dplyr package (Wickham et al., 2015) for data manipulation and the ggplot2 package (Wickham 2016) for plotting. The code used to create each figure can be found at https://github.com/mkc9953/SARS-CoV-2-WW-EPI/tree/master.
INFINITE-DIMENSIONAL GRADIENT-BASED DESCENTFOR ALPHA-DIVERGENCE MINIMISATION
Title
dplyr::coalesce() to replaces NAs with values from other vectors.
Gallagher, J. (2020, October 9). Covid cases increase rapidly as next steps planned. BBC News. https://www.bbc.com/news/health-54477618
Here’s a table showing the tradeoffs:
Comparison of dashboard tech stack as of 10/2020:

The neighbour‐joining tree was prepared with the R package {Ape} (Paradis, Claude, & Strimmer, 2004) and visualized using the R package {ggtree} (Yu, Smith, Zhu, Guan, & Lam, 2017).
aaronpeikert. (2020). Aaronpeikert/reproducible-research [TeX]. https://github.com/aaronpeikert/reproducible-research (Original work published 2019)
Viechtbauer, W. (2020). Wviechtb/forest_emojis [R]. https://github.com/wviechtb/forest_emojis (Original work published 2020)
Kretzschmar, M. E., Rozhnova, G., Bootsma, M. C. J., Boven, M. van, Wijgert, J. H. H. M. van de, & Bonten, M. J. M. (2020). Impact of delays on effectiveness of contact tracing strategies for COVID-19: A modelling study. The Lancet Public Health, 5(8), e452–e459. https://doi.org/10.1016/S2468-2667(20)30157-2
Adam, D. (2020). A guide to R — the pandemic’s misunderstood metric. Nature. https://doi.org/10.1038/d41586-020-02009-w
Starnini, M., Aleta, A., Tizzoni, M., & Moreno, Y. (2020). Impact of the accuracy of case-based surveillance data on the estimation of time-varying reproduction numbers. MedRxiv, 2020.06.26.20140871. https://doi.org/10.1101/2020.06.26.20140871
Wilson, C. (n.d.). First coronavirus R numbers for regions within England released. New Scientist. Retrieved June 15, 2020, from https://www.newscientist.com/article/2246029-first-coronavirus-r-numbers-for-regions-within-england-released/
Farboodi, M., Jarosch, G., & Shimer, R. (2020). Internal and External Effects of Social Distancing in a Pandemic (Working Paper No. 27059; Working Paper Series). National Bureau of Economic Research. https://doi.org/10.3386/w27059
Working with Census microdata. (n.d.). Retrieved July 31, 2020, from https://walker-data.com/tidycensus/articles/pums-data.html
Holcombe, A. O., Kovacs, M., Aust, F., & Aczel, B. (2020). Tenzing: Documenting contributorship using CRediT [Preprint]. MetaArXiv. https://doi.org/10.31222/osf.io/b6ywe
Spiegelhalter, D. (2020, July 5). Risks, R numbers and raw data: How to interpret coronavirus statistics. The Observer. https://www.theguardian.com/world/2020/jul/05/risks-r-numbers-and-raw-data-how-to-interpret-coronavirus-statistics
Liverpool, C. W., Jessica Hamzelou, Adam Vaughan, Conrad Quilty-Harper and Layal. (n.d.). Covid-19 news: Almost 20,000 care home deaths in England and Wales. New Scientist. Retrieved July 6, 2020, from https://www.newscientist.com/article/2237475-covid-19-news-almost-20000-care-home-deaths-in-england-and-wales/
Introducing JASP 0.13. (2020, July 2). JASP - Free and User-Friendly Statistical Software. https://jasp-stats.org/?p=6483
Du, H., Jiang, G., & Ke, Z. (2020). A Bootstrap Based Between-Study Heterogeneity Test in Meta-Analysis [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/de4g9
Matthias #WashYourHands Egger on Twitter: “The effective reproduction number Re is now above 1 in #Switzerland: 1.28 (95% 1.06-1.53). We urgently need an in-depth understanding of transmission dynamics, the effectiveness of contact tracing etc. And #MaskUp https://t.co/24E5o4jYiS” / Twitter. (n.d.). Twitter. Retrieved June 30, 2020, from https://twitter.com/eggersnsf/status/1276882802173247490
Mathur, M. B., & VanderWeele, T. J. (2020). New statistical metrics for multisite replication projects. Journal of the Royal Statistical Society: Series A (Statistics in Society), 183(3), 1145–1166. https://doi.org/10.1111/rssa.12572
Vaughan, A. (n.d.). R number. New Scientist. Retrieved June 29, 2020, from https://www.newscientist.com/term/r-number/
For example, some have de-manded that furries “yiff [derogatory furry term for sexual intercourse] in hell, furfag” (Brookey & Cannon, 2009, p. 159).
See r/yiffinhell on Reddit.
Privacy Preserving Data Analysis of Personal Data (May 27, 2020). (n.d.). Retrieved June 25, 2020, from https://www.youtube.com/watch?time_continue=11&v=wRI84xP0cVw&feature=emb_logo
Maier, M., Bartoš, F., & Wagenmakers, E.-J. (2020). Robust Bayesian Meta-Analysis: Addressing Publication Bias with Model-Averaging [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/u4cns
Coronavirus: R number jumps to 1.79 in Germany after abattoir outbreak. (n.d.). Sky News. Retrieved June 22, 2020, from https://news.sky.com/story/coronavirus-r-number-jumps-to-1-79-in-germany-after-abattoir-outbreak-12011468
How to prevent the environment from being “invalidated”?Docker containers (Rocker)
Rocker
SAS, R, Stata, SPSS may return different results even for quantiles, or due to floating number representation! The results should be maximally close to each other, but what about resampling methods (SAS and R gives different random numbers for the same seed)?
Different results between SAS, R, Stata, SPSS
99.9% open-source. 0.1% is licensed (free for non-commercial use)
License of libraries in R
Status of R on the Clinical Research market
Differences in
Differences between R and SAS:
Tospeeduptheprocesswithoutsacrificingaccuracy,theteamalsousesRevolutionRanalyticproducts
Revolution R
Hironori Funabiki on Twitter
Willem, L., Hoang, T. V., Funk, S., Coletti, P., Beutels, P., & Hens, N. (2020). SOCRATES: An online tool leveraging a social contact data sharing initiative to assess mitigation strategies for COVID-19 [Preprint]. Epidemiology. https://doi.org/10.1101/2020.03.03.20030627
Dablander, F. (2020, June 11). Interactive exploration of COVID-19 exit strategies. R-Bloggers. https://www.r-bloggers.com/interactive-exploration-of-covid-19-exit-strategies/
Ggplot2 extensions. (n.d.). Retrieved June 14, 2020, from https://exts.ggplot2.tidyverse.org/
Views, R. (2020, May 20). An R View into Epidemiology. /2020/05/20/some-r-resources-for-epidemiology/
In most programming languages, you can only access the values of a function’s arguments. In R, you can also access the code used to compute them. This makes it possible to evaluate code in non-standard ways: to use what is known as non-standard evaluation
Bail, C. A. (2016). Combining natural language processing and network analysis to examine how advocacy organizations stimulate conversation on social media. Proceedings of the National Academy of Sciences, 113(42), 11823–11828. https://doi.org/10.1073/pnas.1607151113
Rosenbusch, H., Hilbert, L. P., Evans, A. M., & Zeelenberg, M. (2020). StatBreak: Identifying “Lucky” Data Points Through Genetic Algorithms. Advances in Methods and Practices in Psychological Science, 2515245920917950. https://doi.org/10.1177/2515245920917950
Peikert, A., & Brandmaier, A. M. (2019). A Reproducible Data Analysis Workflow with R Markdown, Git, Make, and Docker. https://doi.org/10.31234/osf.io/8xzqy
Samuel, J.; Ali, G.G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Preprints 2020, 2020050015 (doi: 10.20944/preprints202005.0015.v1)
Davis, N. (2020, May 4). Rival Sage group says Covid-19 policy must be clarified. The Guardian. https://www.theguardian.com/world/2020/may/04/rival-sage-group-covid-19-policy-clarified-david-king
Puleo, M., & Staff Writer (2020 March 18). New study says “high temperature and high relative humidity significantly reduce” spread of COVID-19. https://www.accuweather.com/en/health-wellness/new-study-says-high-temperature-and-high-relative-humidity-significantly-reduce-spread-of-covid-19/703418
Liu, Y., Eggo, R. M., & Kucharski, A. J. (2020). Secondary attack rate and superspreading events for SARS-CoV-2. The Lancet, 395(10227), e47. https://doi.org/10.1016/S0140-6736(20)30462-1
Endo, A., Centre for the Mathematical Modelling of Infectious Diseases COVID-19 Working Group, Abbott, S., Kucharski, A. J., & Funk, S. (2020). Estimating the overdispersion in COVID-19 transmission using outbreak sizes outside China. Wellcome Open Research, 5, 67. https://doi.org/10.12688/wellcomeopenres.15842.1
Carl T. Bergstrom on Twitter
R today - UK
The Santa Fe Institute - SFI Transmission PDF
Bi, Q., Wu, Y., Mei, S., Ye, C., Zou, X., Zhang, Z., Liu, X., Wei, L., Truelove, S. A., Zhang, T., Gao, W., Cheng, C., Tang, X., Wu, X., Wu, Y., Sun, B., Huang, S., Sun, Y., Zhang, J., … Feng, T. (2020). Epidemiology and transmission of COVID-19 in 391 cases and 1286 of their close contacts in Shenzhen, China: A retrospective cohort study. The Lancet Infectious Diseases, S1473309920302875. https://doi.org/10.1016/S1473-3099(20)30287-5
You can create estimation plots here at estimationstats.com, or with the DABEST packages which are available in R, Python, and Matlab.
You can create estimation plots with:
McElreath, R. Statistical Rethinking: A Bayesian Course Using R and Stan Github.com. https://github.com/rmcelreath/statrethinking_winter2019
Entire course with materials online.
R 4.0.0 now available, and a look back at R’s history. (n.d.). Revolutions. Retrieved April 30, 2020, from https://blog.revolutionanalytics.com/2020/04/r-400-is-released.html
James, E. Tutorial Home. Github.io. https://emljames.github.io/GorillaR/
Multilevel correlations: A new method for common problems. (2020 April 13). R-bloggers. https://www.r-bloggers.com/multilevel-correlations-a-new-method-for-common-problems/
Petermr/openVirus. (n.d.). GitHub. Retrieved April 8, 2020, from https://github.com/petermr/openVirus
Pharma, which is one of the biggest, richest, most rewarding and promising industries in the world. Especially now, when the pharmaceutical industry, including the FDA, allows R to be used the domain occupied in 110% by SAS.
Pharma industry is one of the most rewarding industries, especially now
CR is one of the most controlled industries in this world. It's insanely conservative in both used statistical methods and programming. Once a program is written and validated, it may be used for decades. There are SAS macros written in 1980 working still by today without any change. That's because of brilliant backward compatibility of the SAS macro-language. New features DO NOT cause the old mechanisms to be REMOVED. It's here FOREVER+1 day.
Clinical Research is highly conservative, making SAS macros applicable for decades. Unfortunately, that's not the same case with R
Thanks to ggforce, you can enhance almost any ggplot by highlighting data groupings, and focusing attention on interesting features of the plot
2.6 The Normal Distribution
The normal distribution in r
Generating random data
Generating random data in r
Descriptive Statistic
R provides a wide range of functions for obtaining summary statistics. One method of obtaining descriptive statistics is to use the sapply( ) function with a specified summary statistic.
dplyr in R also lets you use a different syntax for querying SQL databases like Postgres, MySQL and SQLite, which is also in a more logical order
We save all of this code, the ui object, the server function, and the call to the shinyApp function, in an R script called app.R
The same basic structure for all Shiny apps:
ui object.server function.shinyApp function.---> examples <---
ui
UI example of a Shiny app (check the code below)
server
Server example of a Shiny app (check the code below):
renderPlotI want to get the selected number of bins from the slider and pass that number into a python method and do some calculation/manipulation (return: “You have selected 30bins and I came from a Python Function”) inside of it then return some value back to my R Shiny dashboard and view that result in a text field.
Using Python scripts inside R Shiny (in 6 steps):
textOutput("textOutput") (after plotoutput()).output$textOutput <- renderText({
}].
library(reticulate).source_python() function will make Python available in R:
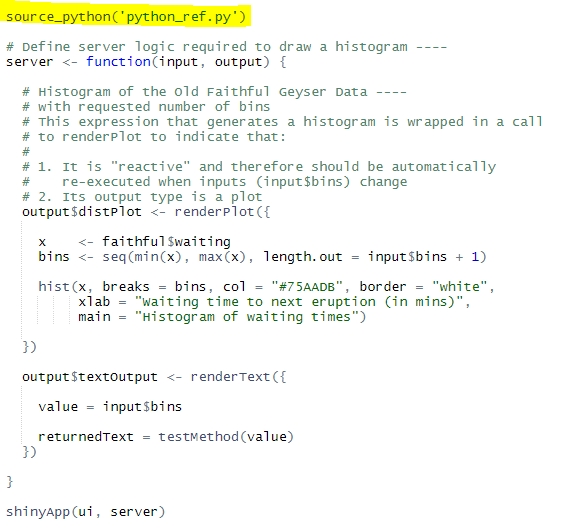
reticulate package to R Environment and sourced the script inside your R code.Hit run.
Currently Shiny is far more mature than Dash. Dash doesn’t have a proper layout tool yet, and also not build in theme, so if you are not familiar with Html and CSS, your application will not look good (You must have some level of web development knowledge). Also, developing new components will need ReactJS knowledge, which has a steep learning curve.
Shiny > Dash:
You can host standalone apps on a webpage or embed them in R Markdown documents or build dashboards. You can also extend your Shiny apps with CSS themes, Html widgets, and JavaScript actions.
Typical tools used for working with Shiny
You can either create a one R file named app.R and create two seperate components called (ui and server inside that file) or create two R files named ui.R and server.R

hec <- within(hec,{
why does he use 'within' rather than mutate?
“A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).”
What is valence in music according to Spotify?
enquo() uses some dark magic to look at the argument, see what the user typed, and return that value as a quosure
neka nota nesto ovdje ima da se doda
missing values are managed, without any pre-processing, by the model used to cluster with the assumption that values are missing completely at random.
VarSelLCM package
Some of the best and cheapest tombstones come from India. In 2013 India produced 35,342 million tons of granite, making it the world’s largest producer
This is interesting to me because I guess I never really thought about where the tombstones came from, I just knew that they came engaved and i never thought about who had to do it
Network centralization
degree.cent <- centr_degree(g, mode = "all") degree.cent$res degree.cent$centralization degree.cent$theoretical_max
I came across this via the cran.r-project, referred to be a computer scientist at an NIH lecture. It might be an interesting source to see code-sharing norms and practices.
Differential analyses for RNA-seq: transcript-level estimates improve gene-level inferences
hi there please check on the Recent Updated SAS Training and Tutorial Course which can explain about the SAS and its integration with the R as well so please go through the Link:-
Beautiful plotting in R: A ggplot2 cheatsheet
Boxplots and Beyond – Part II: Asymmetry
Using the Median Absolute Deviation to Find Outliers
Using foo:::f instead of foo::f allows access to unexported objects.
In the six states that prohibit ex-felons from voting, one in four African-American men is permanently disenfranchised.
Shiny Server: Running with a Proxy
The host parameter was introduced in Shiny 0.9.0.
toxic waste, poison air, beach goo, eroded 215 roads draw nations together
Robert Frosts, Mending Wall
高齡
Updated annotation.
HarvardX Biomedical Data Science Open Online Training
argyle: An R Package for Analysis of Illumina Genotyping Arrays
Updated annotation.
Introduction to R for Data Science
Data analysis course using R
Learn Data Science Online
Data analysis courses using R and Python
Teaching Yourself to Code in DH
The Automated R Instructor
Andreas Ihlebæk: The Guest [oooo]
VÖ: 26.5.2017
Tora: Take A Rest [ooo]
VÖ: 9.6.2017
Nils Wülker: On [ooo]
VÖ: 2.6.2017
National Research Council
The National Research Council (NRC) is an organization within the Government of Canada dedicated to research and development. Today, the NRC works with members of the Canadian industry to provide meaningful research and development for many different types of products. The areas of research and development that the NRC participates in include aerospace, aquatic and crop resource development, automotive and surface transportation, construction, energy, mining, and environment, human health therapeutics, information and communications technologies, measurement science standards, medical devices, astronomy and astrophysics, ocean, coastal, and river engineering, and security and disruptive technologies. The NRC employs scientists, engineers, and business experts. The mission of the NRC is as follows: “Working with clients and partners, we provide innovation support, strategic research, scientific and technical services to develop and deploy solutions to meet Canada's current and future industrial and societal needs.” The main values of the NRC include impact, accountability, leadership, integrity, and collaboration. The most recent success stories of the NRC include research regarding “green buildings,” math games, mechanical insulation, and many more (Government of Canada 2017). Here is a link to their achievement page where these stories and more are posted: http://www.nrc-cnrc.gc.ca/eng/achievements/index.html. Here is a link to the NRC webpage: http://www.nrc-cnrc.gc.ca/eng/index.html.
References
Government of Canada. 2017. National Research Council Canada. May 5. Accessed May 8, 2017. http://www.nrc-cnrc.gc.ca/eng/index.html.
Reciprocity
This one was easy! Getting good a good directed network to play around with it with into R and able to be modified was... way harder than getting this info.
reciprocity(g, ignore.loops = TRUE)
There is an additional mode operator where if you put the mode = ("ratio") it calculates (unordered) vertex pairs are classified into three groups: (1) not-connected, (2) non-reciprocaly connected, (3) reciprocally connected. The result is the size of group (3), divided by the sum of group sizes (2)+(3).
Centralization
Centralization interests me for analyzing discussion forums--are there key players, and do these key players show higher degrees of cognitive presence?
Calculating for centralization by number of connections seems quite straightforward in R: centralization.degree
Clustering
I am very interested in clustering measures, because I plan to analyze data from a Slack group that I am a part of, where I suspect there are many subgroups who only interact with each other.
After looking around for some different clustering algorithms, I found the "cluster_label_prop" function in the igraph package, which seems to do what I would like to do. To summarize, this function automatically detects groups within a network by initially labeling every node with a unique label and at every step each node adopts the label that most of its neighbors currently have. In this iterative process densely connected groups of nodes form a consensus on a unique label to form communities.
There seem to be many different ways to define clustering though, so I am sure that I will need to do more research on the topic of clustering as I move forward with my research project.
the last rain
repeats "last rain" telling the reader there is a drought
See http://kateto.net/network-visualization↩
This is incredible! Thank you for sharing this link.
THE WESTERN LAND, nervous under the beginning change. The Western States, nervous as horses before a thunder storm
Steinbeck groups the Western states together in one entity that feels and experiences the same nervous energy, like that of horses. The repetition of this idea throughout Ch. 14 serves to underscore the unity of these states as a single group separate and distinct from the rest of the country.
Despite many editors being unpaid or poorly remunerated for their work, plant scientist Jaime A. Teixeira da Silva believes they “should be held accountable” if authors are made to wait for an “excessive or unreasonable amount of time” before a decision is made on their research.
How would this be enforced exactly?
The crawler represented a third option: a way to figure out how humans work.
Good way to look at it.
marine species that calcify have survived through millions of years when CO2 was at much higher levels
Some calcifying species were indeed abundant in the Cretaceous, a time at which the atmospheric CO2 concentration was high. However, seawater alkalinity was also high due to intense weathering on land. Hence, the concentration of carbonate ions (CO3, which controls calcification) was elevated. That compensation does not happen today and will not happen in the near future because total alkalinity does not change significantly on time scales of centuries. There is ample evidence in the literature for that.
R made me!
Ensures that vital information is provided to educators, families, students, and communities through annual statewide assessments that measure students' progress toward those high standards.
Naturally, not every student is capable of reaching those high standards but, ability based grouping will help those students reach those standards.
When students are grouped by ability, then collaborative work becomes important because this type of learning environment is heavily dependent on team work.
This prevents the one or two "smart" students in the group from doing all the work because all the students are on the same academic level.
Students can move at their own pace: When students are grouped together based on skill level, the pressure is lessened of when the topic must be covered.
This is probably the most apparent benefit to ability based grouping.
Between-class grouping - a school's practice of separating students into different classes, courses, or course sequences (curricular tracks) based on their academic achievement
This is how i envision the education system should look.
Within-class grouping - a teacher's practice of putting students of similar ability into small groups usually for reading or math instruction
Proponents of ability grouping say that the practice allows teachers to tailor the pace and content of instruction much better to students' needs and, thus, improve student achievement.
Considered by the beef industry to be an impressive innovation, lean finely textured beef is made from the remnant scraps of cattle carcasses that were once deemed too fatty to go into human food.
The textured beef is made of just scraps and waste that was not going to be put into food.
R Grouping functions: sapply vs. lapply vs. apply. vs. tapply vs. by vs. aggregate var ados = ados || {}; ados.run = ados.run || []; ados.run.push(function () { ados_add_placement(22,8277,"adzerk794974851",4).setZone(43); }); up vote 463 down vote favorite 606 Whenever I want to do something "map"py in R, I usually try to use a function in the apply family. (Side question: I still haven't learned plyr or reshape -- would plyr or reshape replace all of these entirely?) However, I've never quite understood the differences between them [how {sapply, lapply, etc.} apply the function to the input/grouped input, what the output will look like, or even what the input can be], so I often just go through them all until I get what I want. Can someone explain how to use which one when? [My current (probably incorrect/incomplete) understanding is... sapply(vec, f): input is a vector. output is a vector/matrix, where element i is f(vec[i]) [giving you a matrix if f has a multi-element output] lapply(vec, f): same as sapply, but output is a list? apply(matrix, 1/2, f): input is a matrix. output is a vector, where element i is f(row/col i of the matrix) tapply(vector, grouping, f): output is a matrix/array, where an element in the matrix/array is the value of f at a grouping g of the vector, and g gets pushed to the row/col names by(dataframe, grouping, f): let g be a grouping. apply f to each column of the group/dataframe. pretty print the grouping and the value of f at each column. aggregate(matrix, grouping, f): similar to by, but instead of pretty printing the output, aggregate sticks everything into a dataframe.] r sapply tapply r-faq
very useful article on apply functions in r
download and install the ACS package in addition to going to requesting a secret key
Troubleshooting csv file - step 1.
R requires forward slashes (/) not back slashes (\) when specifying a file location even if the file is on your hard drive.